[帮助文档] 如何使用HiveJindoSDK处理OSS-HDFS服务中的数据
使用Hive搭建离线数仓时,随着数据量的不断增长,传统的基于HDFS存储的数仓可能无法以较低成本满足用户的需求。在这种情况下,您可以使用OSS-HDFS服务作为Hive数仓的底层存储,并通过JindoSDK获得更好的读写性能。
请问一下 从hdfs load数据到hive中 hive数据全部为null是什么情况呢,hdfs数据
请问一下 从hdfs load数据到hive中 hive数据全部为null是什么情况呢,hdfs数据为json格式,hive中只有一个字段


BigData:大数据开发的简介、核心知识(linux基础+Java/Python编程语言+Hadoop{HDFS、HBase、Hive}+Docker)、经典场景应用之详细攻略
导读:最近几天,有很多很多的网友留言都在咨询——如何学习大数据开发,以及如何跟上大数据时代而不被抛弃。今天周末,博主花了一段时间,统一采用本文章,以Hadoop生态系统布局进行回答,欢迎网友留言提建议。首先,大数定理告诉我们,在试验不变的条件下,重复试验多次...
1.13.6版本 flink sql 写hive 任务正常,hdfs上有文件,但是发现缺乏_SU
1.13.6版本 flink sql 写hive 任务正常,hdfs上有文件,但是发现缺乏_SUCCESS 标记文件,与hive分区也没有创建 ,有谁知道什么原因?
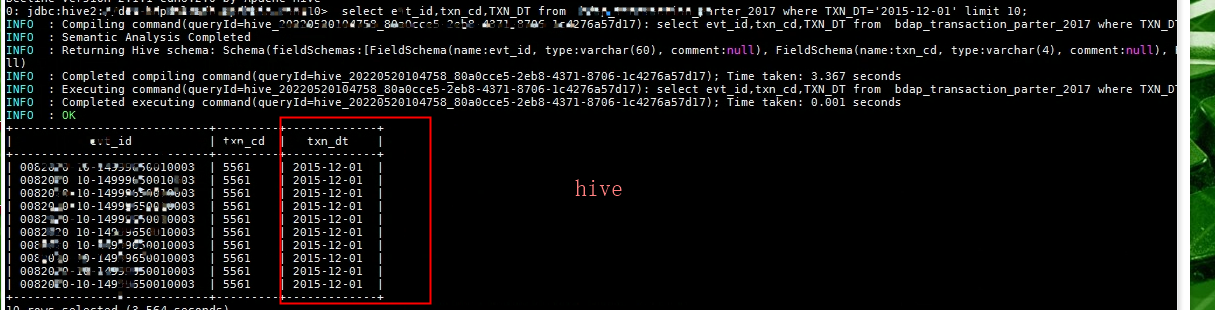
HIVE HDFS 同步到MYSQL里,在HIVE里存为目录的分区键的如何同步呢?
请教下大佬们 ,HIVE HDFS 同步到MYSQL的时候,如果在源端HIVE里是分区表,分区字段要这么同步到目标端MYSQL呢?HIVE端数据情况:TXN_DT为分区键,见附件1同步至MYSQL数据情况见附件2
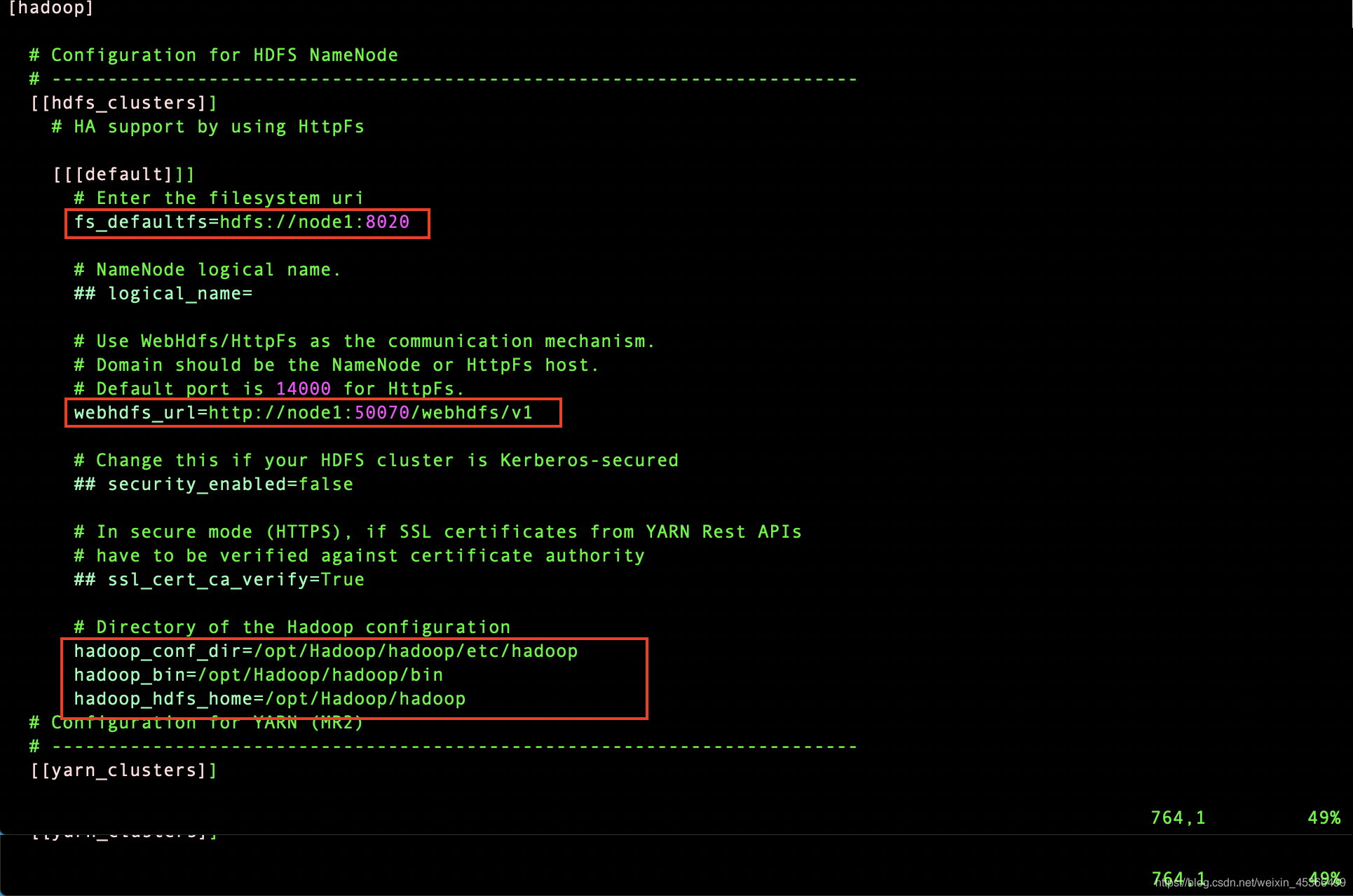
Hue与HDFS、YARN、Hive、MySQL、HBase的集成
一、Hue与HDFS的集成第一步进入到/opt/Hadoop/hue/desktop/conf目录下,修改hue.ini文件修改如下:fs_defaultfs=hdfs://node1:8020 webhdfs_url=http://node1:50070/webhdfs/v1 hadoop_con...
hive当中从hdfs文件系统向表中加载数据怎么做?
hive当中从hdfs文件系统向表中加载数据怎么做?
stream sink hive 在hdfs ha模式下 java.net.UnknownHostE
hi 你好 我这边集群是cdh的。 配置了hdfs ha模式 在使用 kafka sink 到hive 时候找不到nameservices java.lang.IllegalArgumentException: java.net.UnknownHostException: nameservices1...
hive仅作为元数据管理,具体数据不存储在hdfs上
hive仅作为元数据管理,具体数据不存储在hdfs上,通过hivecatalog可以读取到具体的数据吗? 比如hive里面存储了MySQL,Oracle的表元数据信息,可以用hivecatalog读取到具体的表数据吗? *来自志愿者整理的flink邮件归档
发现flinksql写hive比写hdfs慢很多
两个job,都从同一个kafka读数据,一份写入hdfs,一份写入hive,都是分钟分区,并发都是200。运行一段时间后发现写hive要落后hdfs很多,而且hive任务对应的hdfs路径下,某一分区内的文件甚至跨度2个小时之久。大家遇到过这种情况没 附上对应ddl hive: CREATE EXT...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子



文件存储HDFS版更多hive相关
文件存储HDFS版您可能感兴趣
- 文件存储HDFS版版本
- 文件存储HDFS版flink
- 文件存储HDFS版hadoop
- 文件存储HDFS版吞吐量
- 文件存储HDFS版高可靠
- 文件存储HDFS版数据
- 文件存储HDFS版产品
- 文件存储HDFS版分布式文件系统
- 文件存储HDFS版实验
- 文件存储HDFS版操作
- 文件存储HDFS版文件
- 文件存储HDFS版大数据
- 文件存储HDFS版api
- 文件存储HDFS版命令
- 文件存储HDFS版存储
- 文件存储HDFS版集群
- 文件存储HDFS版java
- 文件存储HDFS版架构
- 文件存储HDFS版目录
- 文件存储HDFS版文件存储
- 文件存储HDFS版配置
- 文件存储HDFS版读取
- 文件存储HDFS版原理
- 文件存储HDFS版学习笔记