
数据分享|R语言聚类、文本挖掘分析虚假电商评论数据:K-MEANS(K-均值)、层次聚类、词云可视化
全文链接:http://tecdat.cn/?p=32540 聚类分析是一种常见的数据挖掘方法,已经广泛地应用在模式识别、图像处理分析、地理研究以及市场需求分析。本文主要研究聚类分析算法K-means在电商评论数据中的应用,挖掘出虚假的评论数据(点击文末“阅读原文”获取完整代码数据)。 本文主要帮助...
数据分享|R语言SVM支持向量机、文本挖掘新闻语料情感情绪分类和词云可视化
支持向量机(SVM)是一种机器学习方法,基于结构风险最小化原则,即通过少量样本数据,得到尽可能多的样本数据(点击文末“阅读原文”获取完整代码数据)。 支持向量机对线性问题进行处理,能解决非线性分类问题。本文介绍了R语言中的 SVM工具箱及其支持向量机(SVM)方法,并将其应用于文本情感分析领域,结果...


数据分享|R语言豆瓣数据文本挖掘 神经网络、词云可视化和交叉验证
全文链接:http://tecdat.cn/?p=31544 在网络技术高速发展的背景下,信息纷乱繁杂,如何能够获得需要的文本信息,成了许多企业或组织关注的问题(点击文末“阅读原文”获取完整代码数据)。 该项目以采集的豆瓣电影评论数据(查看文末了解数据免费获取方式)为例,使用R语言和神经网络算法,对...
【数据分享】R语言SVM和LDA文本挖掘分类开源软件存储库标签数据和词云可视化
全文链接:http://tecdat.cn/?p=30413 开源软件存储库上有数千个开源软件,可以从中免费使用该软件。为了能够有效和高效地识别用户所需的软件,已根据软件的功能和属性向软件判断了标记(点击文末“阅读原文”获取完整代码数据)。 因此,标签分配成为开源软件存储库软件维护成功的关键。手动分...
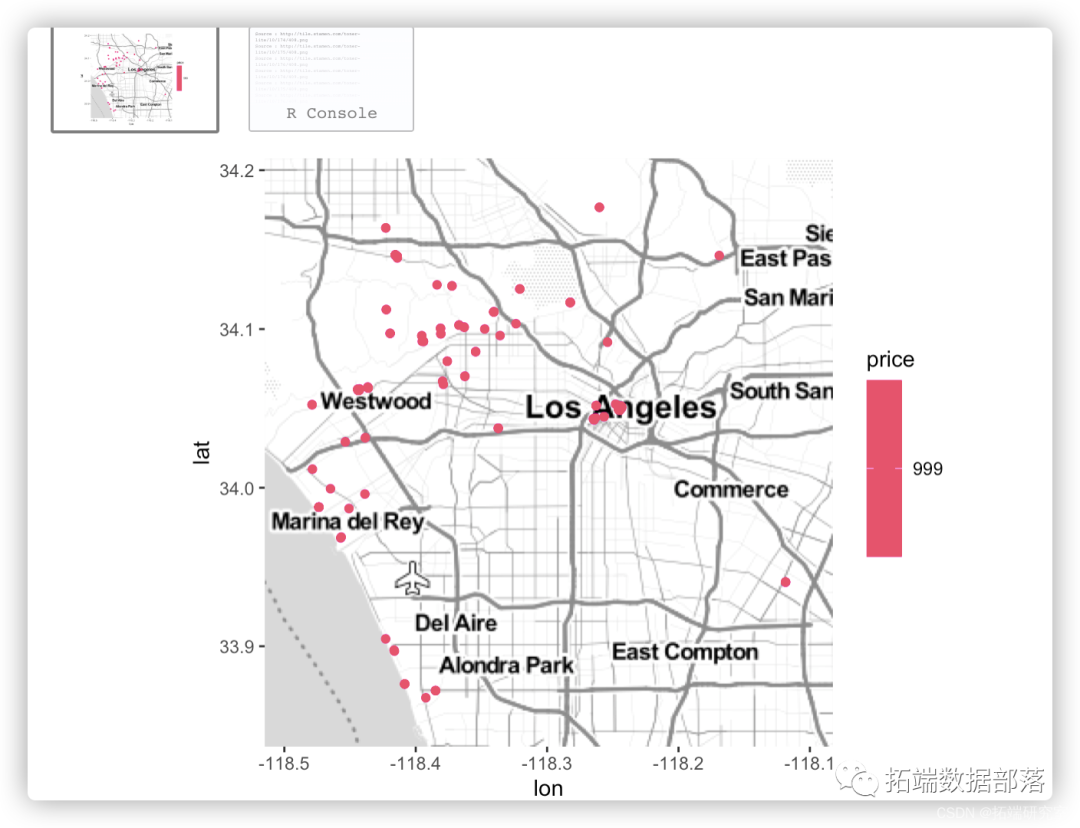
【数据分享】R语言对airbnb数据nlp文本挖掘、地理、词云可视化、回归GAM模型、交叉验证分析
全文链接:http://tecdat.cn/?p=27976 作者:Guojiang Zhao 数据量大,数据要进行清洗以及预处理,同时要多方面可视化,要探索多变量对因变量的影响。 解决方案 用R语言读取数据(查看文末了解数据获取方式),对数据进行...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
r语言数据相关内容
- r语言因子分析数据
- r语言数据代码
- r语言数据可视化分析
- r语言实战数据代码可视化详细分析
- r语言实战数据
- r语言聚类分析数据
- 线性模型r语言数据
- 可视化r语言实例数据
- r语言区间数据
- 视频r语言实例数据
- r语言svr数据
- r语言向量数据
- r语言检验数据
- r语言贝叶斯数据
- r语言stan贝叶斯数据
- r语言模型数据
- 数据r语言案例
- 数据r语言
- r语言数据可视化数据
- r语言分类数据可视化数据
- r语言分类数据
- r语言基因数据
- r语言多维数据
- r语言层次聚类数据
- r语言可视化实例数据
- r语言可视化数据
- r语言线性数据
- r语言线性模型数据
- 数据r语言树
- 数据r语言支持向量机
- 数据r语言树流失
- 数据r语言研究
- r语言主成分数据
- r语言神经网络数据
- r语言神经网络可视化数据
- r语言聚类数据
- r语言信用数据
- r语言主成分pca数据
- r语言数据实例
- r语言pca主成分数据
- r语言分析数据
- r语言pca数据
- r语言网络数据
- r语言gam分析数据
- r语言逻辑回归数据
- r语言gam数据
- r语言knn数据
- r语言房价数据
- r语言逻辑回归分类数据
r语言更多数据相关
- r语言模型分析数据
- jupyter notebook r语言数据
- 数据科学r语言数据
- 数据r语言逻辑回归
- 数据r语言模型
- r语言时间序列数据
- 数据r语言可视化
- r语言逻辑回归分析数据
- r语言心脏病数据
- r语言线性回归数据
- 数据r语言序列
- 数据r语言数据可视化
- r语言工资数据
- r语言树数据
- r语言调查数据
- r语言随机森林数据
- r语言数据检验
- 数据r语言主成分
- r语言文本挖掘数据
- r语言泊松数据
- 数据r语言电影
- 数据r语言聚类
- r语言序列数据可视化
- 数据r语言泊松
- 数据r语言决策随机森林
- 数据r语言广义逻辑回归
- r语言lda数据
- r语言检验分析数据
- r语言svm数据
- r语言树随机森林数据
- 数据r语言逻辑回归决策树
- 视频r语言工资数据
- r语言指数数据
- 数据代码r语言
- 数据r语言主成分pca
- r语言文本数据
- r语言序列数据
- r语言随机森林心脏病数据
- r语言缺失数据
- r语言交易数据
- 数据r语言arima
- 数据r语言广义glm逻辑回归
- 数据r语言变换
- r语言逻辑回归logistic数据
- r语言逻辑回归数据可视化
- 数据r语言广义线性模型泊松
- r语言线性模型逻辑回归数据
- r语言汽车数据
- 数据r语言roc
- 数据r语言svm分类