Python Selenium 爬虫淘宝案例
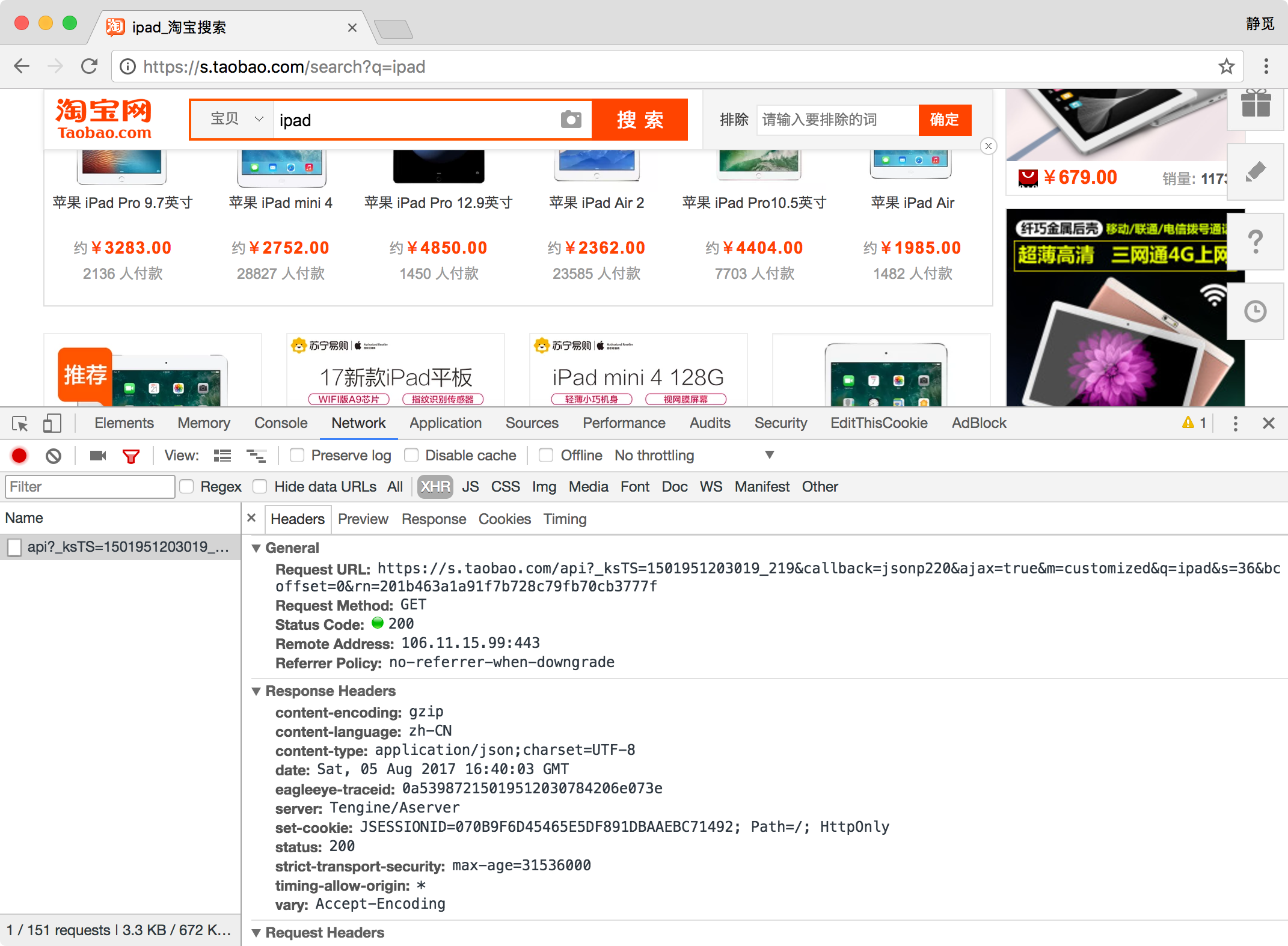
前言 在前一章中,我们已经成功尝试分析 Ajax 来抓取相关数据,但是并不是所有页面都可以通过分析 Ajax 来完成抓取。比如,淘宝,它的整个页面数据确实也是通过 Ajax 获取的,但是这些 Ajax 接口参数比较复杂,可能会包含加密密钥等,所以如果想自己构造 Ajax 参数,还是比较困难的。对于这...
Python+Selenium 爬虫详解
前言在实现爬虫时,解决反爬问题是我们经常要面对的。如果使用传统的 Requests 模块进行爬虫,我们要详细研究请求方法、请求参数等内容。而如果我们使用 Selenium 进行爬虫,我们只需要关注用户的操作,我们可以模拟人操作浏览器。这样我们就可以减少很多应付反爬的内容。文章内容如下:下载 Web ...

python selenium chrome 只要打开 就被反爬虫?报错
有个网站 只要我用 chrome 驱动开打网址 就被检测到, 拖动滑块验证 一直 是失败。 换回 手动打开 浏览器 就能 正常拖动滑块验证。 IP 每次我都是更换的。 浏览器和 驱动 都从新下载的别的版本 还是不行。 求大神 指点已下 谢谢了。以前没遇到过这个情况...
Python Selenium爬虫实现歌曲免费下载
最近发现越来越多的歌曲下载都需要缴费了,对维护正版是好事。但有的时候也想钻个空子,正好最近在学习python,随手写了一个建议爬虫,用来爬取某播放软件的在线音乐。 主要思路就是爬取播放页里的播放源文件的url,程序可以读取用户输入并返回歌单,,,因为在线网站包含大量js,requests就显得很无奈...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python爬虫相关内容
- Python爬虫beautifulsoup
- Python爬虫程序
- Python爬虫策略
- 数据采集Python爬虫
- Python爬虫代理
- Python爬虫ip
- Python爬虫伪装
- Python爬虫代理ip
- Python爬虫商品
- Python爬虫京东
- Python爬虫appium
- Python爬虫app
- Python爬虫微信朋友圈
- Python爬虫爬取
- Python爬虫微信
- Python爬虫爬取微信
- Python爬虫mitmproxy
- Python爬虫charles
- Python爬虫cookies
- Python爬虫登录
- Python爬虫github
- Python爬虫文章
- Python爬虫付费
- Python爬虫代理池
- Python爬虫原理
- Python爬虫验证码识别
- Python爬虫验证码
- Python爬虫滑动验证
- Python爬虫项目
- Python爬虫实例
- Python爬虫请求
- Python爬虫技术
- Python爬虫工具
- Python爬虫数据
- Python爬虫实战
- Python爬虫数据爬取
- Python爬虫agent
- Python web爬虫
- Python爬虫分析
- Python爬虫数据采集分析
- Python爬虫数据采集
- Python爬虫实战多多商品数据分析
- Python爬虫数据分析
- Python爬虫splash
- Python爬虫源码
- Python爬虫源码总有
- Python爬虫数据抓取
- Python爬虫实战分析
- Python爬虫网页
Python更多爬虫相关
- Python爬虫库
- Python爬虫抓取
- Python爬虫scrapy
- Python爬虫入门
- Python爬虫解析
- Python爬虫入门教程
- Python爬虫urllib
- Python爬虫框架项目实战
- Python爬虫入门教程爬取
- Python爬虫电影
- Python爬虫xpath
- Python爬虫百度
- Python爬虫采集
- Python爬虫入门教程数据抓取
- Python爬虫请求头
- Python爬虫requests库
- Python爬虫线程
- Python技术爬虫
- Python爬虫技术框架
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫get
- Python爬虫csdn
- Python爬虫ajax
- Python爬虫基础
- Python爬虫入门教程图片爬取
- Python爬虫入门教程图片
- Python爬虫报错
- Python爬虫数据库
- Python爬虫入门教程scrapy
- Python爬虫post
- Python爬虫解析网页
- Python爬虫get请求
- Python爬虫区别
- Python爬虫功能
- Python爬虫scrapy设置
- Python爬虫beautifulsoup4
- Python爬虫学习
- Python爬虫入门教程数据scrapy
- Python爬虫进程
- Python爬虫网站
- Python爬虫基本原理
- Python爬虫Scrapy框架
- Python爬虫页面
- Python爬虫入门教程技术
- Python网络爬虫selenium
- Python爬虫http
- Python爬虫豆瓣电影
- Python爬虫分布式
- Python爬虫入门教程多线程爬取