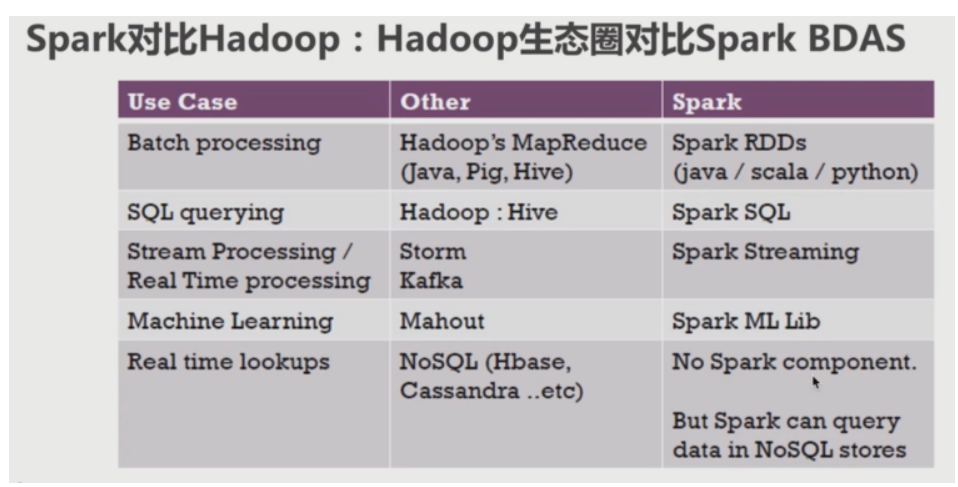
大数据进阶之路——Spark SQL基本配置
文章目录Spark安装编译失败环境搭建Standalone本地IDEHiveContextAPPSparkSessinonSpark ShellSpark Sqlthriftserver/beeline的使用jdbcMapReduce的局限性:1)代码繁琐;2)只能够支持map和reduce方法;3...
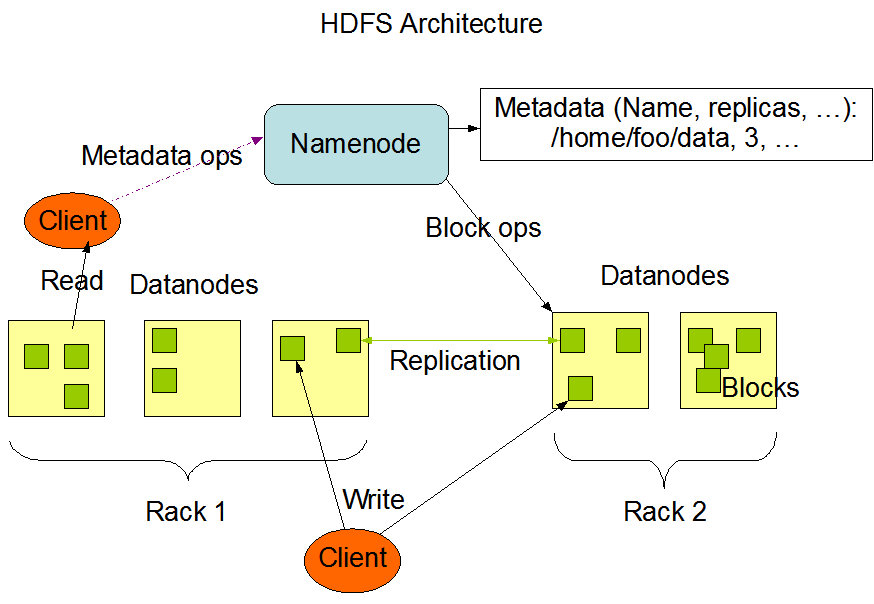
大数据进阶之路——Spark SQL环境搭建
@[toc]大数据概述定义和特征海量的计算大量的用户全体数据分析数据管理4V特征1.Volume(大量) 截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。2.Vel...

大数据为什么那么火?一文带你了解Spark与SQL结合的力量
Spark是一种大规模、快速计算的集群平台,本头条号试图通过学习Spark官网的实战演练笔记提升笔者实操能力以及展现Spark的精彩之处。有关框架介绍和环境配置可以参考以下内容: linux下Hadoop安装与环境配置(附详细步骤和安装包下载) linux下Spark安装与环境配置(附详细步...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子








云原生大数据计算服务 MaxComputespark相关内容
- 云原生大数据计算服务 MaxCompute引擎spark
- 云原生大数据计算服务 MaxCompute spark模式
- 云原生大数据计算服务 MaxCompute hive spark
- 云原生大数据计算服务 MaxCompute spark任务
- 云原生大数据计算服务 MaxCompute spark resource
- 云原生大数据计算服务 MaxCompute框架spark
- spark云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark运行
- aigc云原生大数据计算服务 MaxCompute spark
- spark云原生大数据计算服务 MaxCompute资源
- 数据计算云原生大数据计算服务 MaxCompute spark访问oss
- 云原生大数据计算服务 MaxCompute spark区别
- 数据计算云原生大数据计算服务 MaxCompute spark oss
- 云原生大数据计算服务 MaxCompute spark程序访问
- 数据计算云原生大数据计算服务 MaxCompute spark程序访问
- 云原生大数据计算服务 MaxCompute spark local
- 云原生大数据计算服务 MaxCompute spark配置
- 云原生大数据计算服务 MaxCompute离线spark
- 云原生大数据计算服务 MaxCompute spark生态圈
- 云原生大数据计算服务 MaxCompute spark编程
- 云原生大数据计算服务 MaxCompute spark概念
- 云原生大数据计算服务 MaxCompute spark源码
- 云原生大数据计算服务 MaxCompute spark倒排索引实战
- 云原生大数据计算服务 MaxCompute spark流程
- 云原生大数据计算服务 MaxCompute spark优势
- 云原生大数据计算服务 MaxCompute spark数据模型
- 云原生大数据计算服务 MaxCompute spark编程模型
- 数据计算云原生大数据计算服务 MaxCompute spark节点
- 云原生大数据计算服务 MaxCompute spark企业级
- spark引擎云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute运行spark
- 云原生大数据计算服务 MaxCompute spark hbase
- 云原生大数据计算服务 MaxCompute spark ha
- 云原生大数据计算服务 MaxCompute spark概述
- 云原生大数据计算服务 MaxCompute spark dataframe dataset常用操作
- 云原生大数据计算服务 MaxCompute spark mllib
- 云原生大数据计算服务 MaxCompute spark数据分析
- 云原生大数据计算服务 MaxCompute spark streaming queries
- 云原生大数据计算服务 MaxCompute spark streaming
- 云原生大数据计算服务 MaxCompute spark structured streaming
- 云原生大数据计算服务 MaxCompute spark external datasource
- 云原生大数据计算服务 MaxCompute spark rdd函数
- 云原生大数据计算服务 MaxCompute spark rdd
- 云原生大数据计算服务 MaxCompute spark应用开发
- 云原生大数据计算服务 MaxCompute spark standalone集群
- 云原生大数据计算服务 MaxCompute spark space
- 部署云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute环境spark
云原生大数据计算服务 MaxCompute更多spark相关
- 云原生大数据计算服务 MaxCompute spark mc参数
- 云原生大数据计算服务 MaxCompute spark设置
- 云原生大数据计算服务 MaxCompute spark jar包
- 云原生大数据计算服务 MaxCompute spark executor
- 云原生大数据计算服务 MaxCompute spark版本
- 云原生大数据计算服务 MaxCompute spark yarn命令
- 云原生大数据计算服务 MaxCompute学习spark项目实战
- 云原生大数据计算服务 MaxCompute spark特性
- 云原生大数据计算服务 MaxCompute spark storm
- 云原生大数据计算服务 MaxCompute spark任务参数
- 云原生大数据计算服务 MaxCompute spark打包
- 云原生大数据计算服务 MaxCompute spark场景
- spark云原生大数据计算服务 MaxCompute科学
- 云原生大数据计算服务 MaxCompute进阶spark sql
- 六六云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute spark vs
- 云原生大数据计算服务 MaxCompute spark单机
- kubernetes spark云原生大数据计算服务 MaxCompute
- spark云原生大数据计算服务 MaxCompute案例
- 开源云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品spark
- 云原生大数据计算服务 MaxCompute spark配置项
- 云原生大数据计算服务 MaxCompute spark设置参数
- 云原生大数据计算服务 MaxCompute spark功能
- 云原生大数据计算服务 MaxCompute spark开源
- 云原生大数据计算服务 MaxCompute spark系统bdas
- 云原生大数据计算服务 MaxCompute spark调优
- 云原生大数据计算服务 MaxCompute spark参数作用
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute实例id
- 云原生大数据计算服务 MaxCompute日期格式
- 云原生大数据计算服务 MaxCompute在建
- 云原生大数据计算服务 MaxCompute client
- 云原生大数据计算服务 MaxCompute openapi
- 云原生大数据计算服务 MaxCompute quickbi
- 云原生大数据计算服务 MaxCompute区分
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute字符
- 云原生大数据计算服务 MaxCompute工单
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute产品