[帮助文档] 数据查询DQL和数据操作DML的架构设计核心要点
为了方便用户操作Transactional Table 2.0,MaxCompute计算引擎对SQL全套的数据查询DQL语法和数据操作DML语法进行了支持,并且SQL引擎内核模块包括Compiler、Optimizer、Runtime等都做了专门适配开发以支持相关功能和优化。本文为您介绍数据查询DQ...
[帮助文档] MaxCompute近实时增全量一体化架构介绍
面对当前日益复杂且对数据时效性要求极高的近实时业务场景,MaxCompute基于Transaction Table2.0推出了集大规模存储、高效批量处理和近实时能力于一体的近实时增量一体化架构。本文为您介绍该架构的工作原理及其优势。

[帮助文档] 高并发近实时增量写入场景的架构设计的基本概念
数据流入Transactional Table 2.0主要存在近实时增量写入和批量写入两种场景,本文为您介绍高并发近实时增量写入场景的架构设计。
[帮助文档] 什么是TransactionTable2.0,有哪些基本概念
Transaction Table2.0的增量存储和处理架构的特殊设计主要集中在五个模块:数据接入、计算引擎、数据优化服务、元数据管理、数据文件组织,其他部分与MaxCompute通用的架构一致。本文为您介绍Transaction Table2.0的核心架构要点。
[帮助文档] EMRServerlessStarRocks产品架构介绍_EMR Serverless StarRocks_开源大数据平台 E-MapReduce(EMR)
本文为您介绍EMR Serverless StarRocks的架构。
【大数据技术Hadoop+Spark】Hive数据仓库架构、优缺点、数据模型介绍(图文解释 超详细)
一、Hive简介Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言使用者则难度较大。因此Facebook...
【大数据技术Hadoop+Spark】HDFS概念、架构、原理、优缺点讲解(超详细必看)
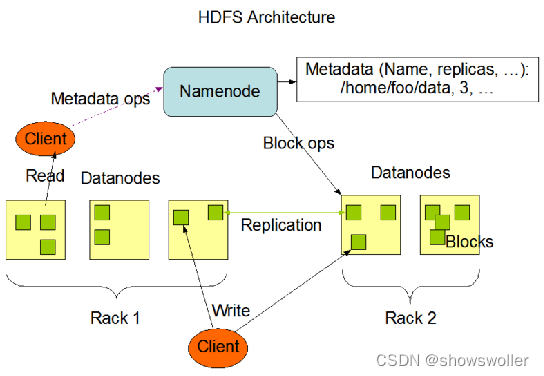
一、相关基本概念文件系统。文件系统是操作系统提供的用于解决“如何在磁盘上组织文件”的一系列方法和数据结构。分布式文件系统。分布式文件系统是指利用多台计算机协同作用解决单台计算机所不能解决的存储问题的文件系统。如单机负载高、数据不安全等问题。HDFS。英文全称为Hadoop Distributed F...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子




最佳实践





架构大数据相关内容
- 大数据架构最佳实践
- 大数据架构hadoop
- 大数据maxcompute架构
- 大数据hadoop hive架构
- spark大数据架构
- 大数据平台cdp架构大数据发展趋势
- 大数据数据采集架构
- 大数据架构目录
- 数据湖大数据lambda架构
- hadoop架构大数据
- 大数据日志分析架构
- 大数据hbase架构
- 大数据仓库架构
- tablestore大数据架构
- lambda大数据架构
- 大数据架构数据平台
- maxcompute大数据架构
- 大数据hdfs hbase架构
- 大数据数据分析架构探究
- 大数据风控架构
- 大数据架构storm
- 峰会大数据架构
- 大数据电商系统架构
- 大数据引擎greenplum架构
- 大数据导论架构