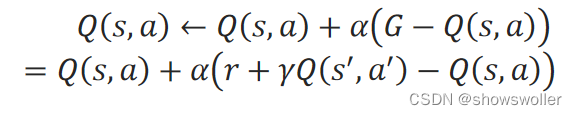
【Python强化学习】时序差分法Sarsa算法和Qlearning算法在冰湖问题中实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~时序差分算法时序差分法在一步采样之后就更新动作值函数Q(s,a),而不是等轨迹的采样全部完成后再更新动作值函数。在时序差分法中,对轨迹中的当前步的(s,a)的累积折扣回报G,用立即回报和下一步的(s^′,a^′)的折扣动作值函数之和r+γQ(s^′,a^′...
【PyTorch深度强化学习】TD3算法(双延迟-确定策略梯度算法)的讲解及实战(超详细 附源码)
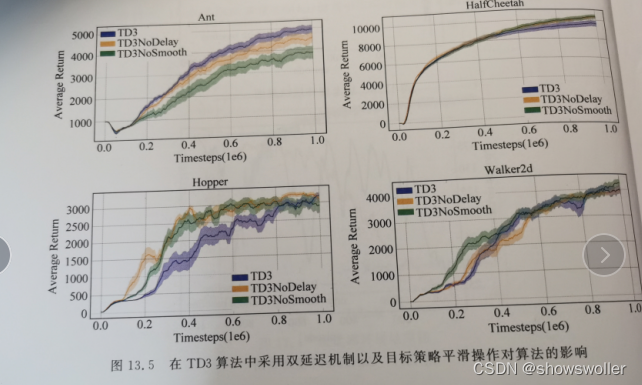
需要源码请点赞关注收藏后评论区留言~~~一、双延迟-确定策略梯度算法在DDPG算法基础上,TD3算法的主要目的在于解决AC框架中,由函数逼近引入的偏差和方差问题。一方面,由于方差会引起过高估计,为解决过高估计问题,TD3将截断式双Q学习(clipped Double Q-Learning)应用于AC...


【PyTorch深度强化学习】DDPG算法的讲解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言留下QQ~~~一、DDPG背景及简介 在动作离散的强化学习任务中,通常可以遍历所有的动作来计算动作值函数q(s,a)q(s,a),从而得到最优动作值函数q∗(s,a)q∗(s,a) 。但在大规模连续动作空间中,遍历所有动作是不现实,且计算代价过大。针对解决连续动作...
深度强化学习中Double DQN算法(Q-Learning+CNN)的讲解及在Asterix游戏上的实战(超详细 附源码)
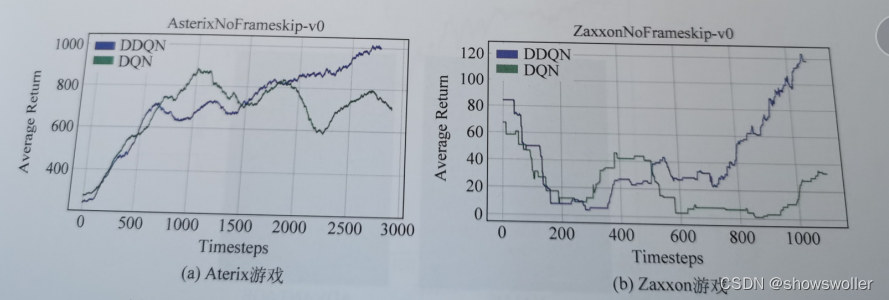
需要源码和环境搭建请点赞关注收藏后评论区留下QQ~~~一、核心思想针对DQN中出现的高估问题,有人提出深度双Q网络算法(DDQN),该算法是将强化学习中的双Q学习应用于DQN中。在强化学习中,双Q学习的提出能在一定程度上缓解Q学习带来的过高估计问题。DDQN的主要思想是在目标值计算时将动作的选择和评...

深度强化学习中利用N-步TD预测算法在随机漫步应用中实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留下QQ或者私信~~~一、N-步TD预测N步TD预测算法在TD(0)和MC之间架起了一座桥梁,而TD(L)算法则能进一步实现两者之间的无缝衔接。下面介绍N步TD预测N步TD算法更新方式介于TD(0)和MC之间,该类算法利用未来多步奖赏和多部之后的值函数估计求得目标值,例...

深度强化学习中利用Q-Learngin和期望Sarsa算法确定机器人最优策略实战(超详细 附源码)
需要源码和环境搭建请点赞关注收藏后评论区留下QQ~~~一、Q-Learning算法Q-Learning算法中动作值函数Q的更新方向是最优动作值函数q,而与Agent所遵循的行为策略无关,在评估动作值函数Q时,更新目标为最优动作值函数q的直接近似,故需要遍历当前状态的所有动作,在所有状态都能被无限次访...
深度强化学习之gym扫地机器人环境的搭建(持续更新算法,附源码,python实现)
想要源码可以点赞关注收藏后评论区留下QQ邮箱本次利用gym搭建一个扫地机器人环境,描述如下:在一个5×5的扫地机器人环境中,有一个垃圾和一个充电桩,到达[5,4]即图标19处机器人捡到垃圾,并结束游戏。同时获得+3的奖赏。左下角[1,1]处有一个充电桩,机器人到达充电桩可以充电且不再行走,获得+1的...
深度强化学习之gym扫地机器人环境的搭建(持续更新算法,附源码,python实现)
想要源码可以点赞关注收藏后评论区留下QQ邮箱本次利用gym搭建一个扫地机器人环境,描述如下:在一个5×5的扫地机器人环境中,有一个垃圾和一个充电桩,到达[5,4]即图标19处机器人捡到垃圾,并结束游戏。同时获得+3的奖赏。左下角[1,1]处有一个充电桩,机器人到达充电桩可以充电且不再行走,获...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









