
【Python机器学习】决策树、K近邻、神经网络等模型对Kaggle房价预测实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~超参数调优超参数调优需要依靠试验的方法,以及人的经验。对算法本身的理解越深入,对实现算法的过程了解越详细,积累了越多的调优经验,就越能够快速准确地找到最合适的超参数试验的方法,就是设置了一系列超参数之后,用训练集来训练并用验证集来检验,多次重复以上...
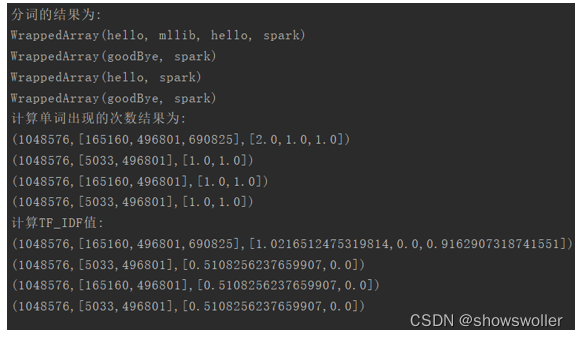
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词...
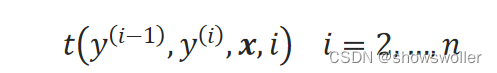
【Python机器学习】条件随机场模型CRF及在中文分词中实战(附源码和数据集)
需要源码请点赞关注收藏后评论区留言私信~~~基本思想假如有另一个标注序列(代词 动词 名词 动词 动词),如何来评价哪个序列更合理呢?条件随机场的做法是给两个序列“打分”,得分高的序列被认为是更合理的。既然要打分,那就要有“评价标准”,称为特征函数。例如,可以定义相邻两个词的词性的关系为一个特征函数...
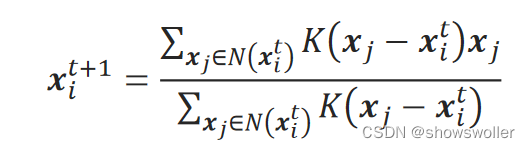
【Python机器学习】Mean Shift、Kmeans聚类算法在图像分割中实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~Mean Shift算法是根据样本点分布密度进行迭代的聚类算法,它可以发现在空间中聚集的样本簇。簇中心是样本点密度最大的地方。Mean Shift算法寻找一个簇的过程是先随机选择一个点作为初始簇中心,然后从该点开始,始终向密度大的方向持续迭代前进,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。


机器学习平台 PAI数据集相关内容
- 机器学习平台 PAI数据集评估
- 机器学习平台 PAI源码数据集
- 机器学习平台 PAI数据集sklearn
- python机器学习平台 PAI数据集
- 机器学习平台 PAI数据集示例
- mllib机器学习平台 PAI数据集
- 机器学习平台 PAI卷积神经网络数据集
- 数据集机器学习平台 PAI
- 机器学习平台 PAI鸢尾花数据集
- 机器学习平台 PAI sklearn数据集
- 机器学习平台 PAI决策树算法数据集
- 机器学习平台 PAI数据集lightgbm
- 机器学习平台 PAI数据集朴素贝叶斯
- 机器学习平台 PAI数据集权限
- 机器学习平台 PAI特征工程数据集
- ml机器学习平台 PAI数据集
- 机器学习平台 PAIsklearn数据集
- 机器学习平台 PAI数据集拆分
- 机器学习平台 PAI数据集拆分格式
- 机器学习平台 PAI线性回归knn数据集
- 机器学习平台 PAIpca数据集降维
- 机器学习平台 PAIpca数据集
- 机器学习平台 PAI笔记数据集
- 机器学习平台 PAI数据集大合辑
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI论文
- 机器学习平台 PAI代码
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI构建
- 机器学习平台 PAI模型
- 机器学习平台 PAIpai
- 机器学习平台 PAI升级
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI分类
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI平台
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践