![机器学习 - [源码实现决策树小专题]决策树中子数据集的划分(不允许调用sklearn等库的源代码实现)](https://ucc.alicdn.com/pic/developer-ecology/drgdp2rj2g4eq_9aa37d44a4ef4df68c21fcc49b2c80eb.png)
机器学习 - [源码实现决策树小专题]决策树中子数据集的划分(不允许调用sklearn等库的源代码实现)
决策树算法中子数据集的划分推荐: 本文中的代码另外有采用了TypeScript/JavaScript进行实现的版本。作者关注到,谷歌TensorFlow团队近几年在JavaScript语言上动作频频,自推出同接口的JavaSccript版本TensorFlow.js后,在2020年先后右推出与Pan...

【Python机器学习】K-Means对文本聚类和半环形数据聚类实战(附源码和数据集)
需要全部代码请点赞关注收藏后评论区留言私信~~~K-Mean算法,即 K 均值算法,是一种常见的聚类算法。算法会将数据集分为 K 个簇,每个簇使用簇内所有样本均值来表示,将该均值称为“质心”。K-Means++,算法受初始质心影响较小;表现上,往往优于 K-Means 算法;与 K-Means算法不...
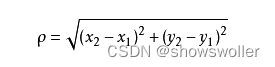
【Python机器学习】感知器进行信用分类和使用KNN进行图书推荐实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、KNN进行图书推荐KNN算法思想简介KNN 可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一。注意:KNN 算法是有监督学习中的分类算法,它看起来和另一个机器学习算法 K-means 有点像(K-means 是无监督学习算法),但...
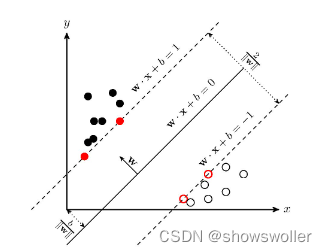
【Python机器学习】SVM解决非线性问题和信用卡欺诈检测实战(附源码和数据集)
需要全部源码和数据集请点赞关注收藏后评论区留言私信~~~SVM简介支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习...
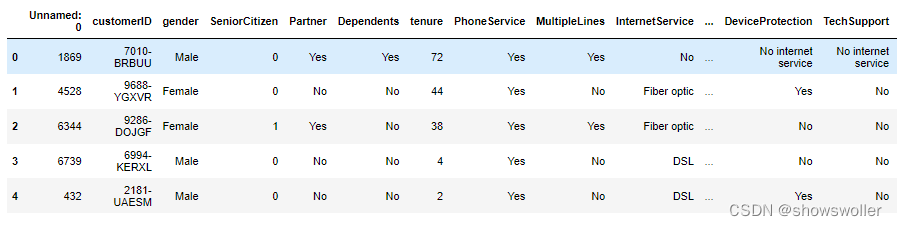
【Python机器学习】决策树、逻辑回归、神经网络等模型对电信用户流失分类实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~电信用户流失分类该实例数据来自kaggle,它的每一条数据为一个用户的信息,共有21个有效字段,其中最后一个字段Churn标志该用户是否流失1:数据初步分析 可用pandas的read_csv()函数来读取数据,用DataFrame的he...

【Python机器学习】决策树、K近邻、神经网络等模型对Kaggle房价预测实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~超参数调优超参数调优需要依靠试验的方法,以及人的经验。对算法本身的理解越深入,对实现算法的过程了解越详细,积累了越多的调优经验,就越能够快速准确地找到最合适的超参数试验的方法,就是设置了一系列超参数之后,用训练集来训练并用验证集来检验,多次重复以上...
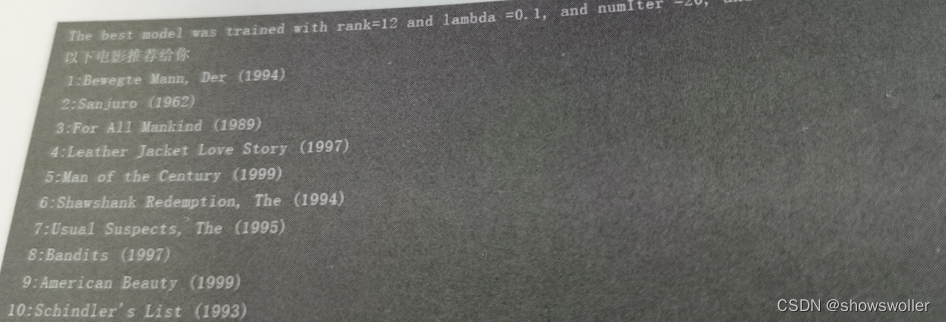
【大数据技术】Spark MLlib机器学习协同过滤电影推荐实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~协同过滤————电影推荐协同过滤是利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。在协同过滤算法中有着两个分支,分别是基于群体用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。在电影推荐系统中,通常分为针对用户推荐电...

【大数据技术】Spark MLlib机器学习线性回归、逻辑回归预测胃癌是否转移实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~线性回归过工具类MLUtils加载LIBSVM格式样本文件,每一行的第一个是真实值y,有10个特征值x,用1:double,2:double分别标注,即建立需求函数:y=a_1x_1+a_2x_2+a_3x_3+a_4x_4+…+a_10x_10通...
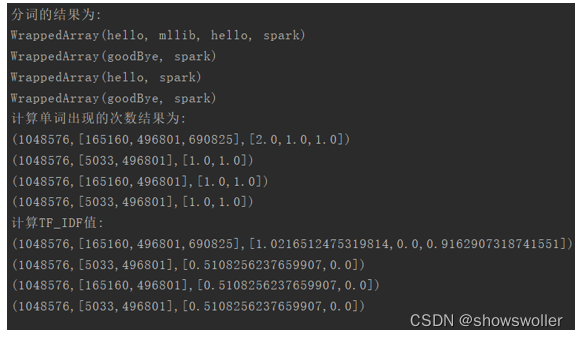
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词...
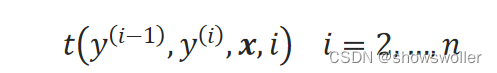
【Python机器学习】条件随机场模型CRF及在中文分词中实战(附源码和数据集)
需要源码请点赞关注收藏后评论区留言私信~~~基本思想假如有另一个标注序列(代词 动词 名词 动词 动词),如何来评价哪个序列更合理呢?条件随机场的做法是给两个序列“打分”,得分高的序列被认为是更合理的。既然要打分,那就要有“评价标准”,称为特征函数。例如,可以定义相邻两个词的词性的关系为一个特征函数...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。


机器学习平台 PAI数据集相关内容
- 机器学习平台 PAI数据集评估
- 机器学习平台 PAI数据集sklearn
- python机器学习平台 PAI数据集
- 机器学习平台 PAI数据集示例
- 机器学习平台 PAI附源码数据集
- mllib机器学习平台 PAI数据集
- 机器学习平台 PAI卷积神经网络数据集
- 数据集机器学习平台 PAI
- 机器学习平台 PAI鸢尾花数据集
- 机器学习平台 PAI sklearn数据集
- 机器学习平台 PAI决策树算法数据集
- 机器学习平台 PAI数据集lightgbm
- 机器学习平台 PAI数据集朴素贝叶斯
- 机器学习平台 PAI数据集权限
- 机器学习平台 PAI特征工程数据集
- ml机器学习平台 PAI数据集
- 机器学习平台 PAIsklearn数据集
- 机器学习平台 PAI数据集拆分
- 机器学习平台 PAI数据集拆分格式
- 机器学习平台 PAI线性回归knn数据集
- 机器学习平台 PAIpca数据集降维
- 机器学习平台 PAIpca数据集
- 机器学习平台 PAI笔记数据集
- 机器学习平台 PAI数据集大合辑
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI论文
- 机器学习平台 PAI代码
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI构建
- 机器学习平台 PAI模型
- 机器学习平台 PAIpai
- 机器学习平台 PAI升级
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI分类
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI平台
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践