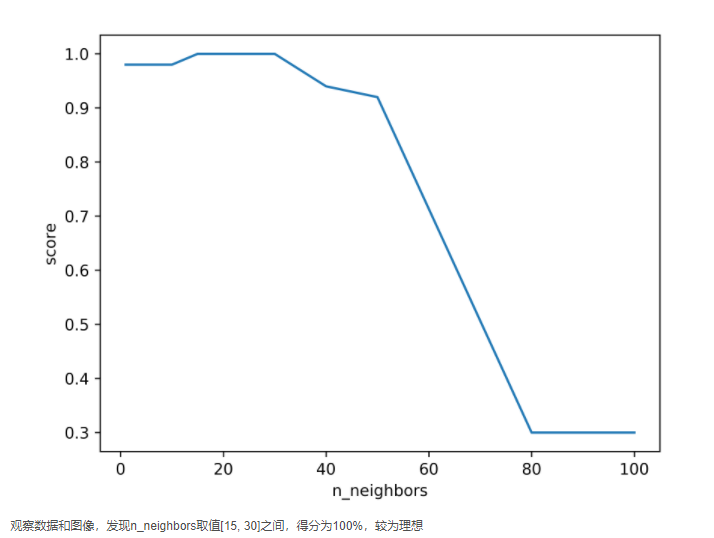
机器学习:K-近邻算法对鸢尾花数据进行分类预测
K-近邻算法 KNN定义:如果一个样本在特征空间中的k个最相似(即特征空间中最近邻)的样本中的大多数属于某一个类别,则改样本也属于这个类别计算距离:欧式距离z = sqrt((x1-x2)^2 + (y1-y2)^2)相似样本,特征之间的值应该都是相近的需要做标准化处理k的取值k较小 容易受异常点....

python机器学习_近邻算法_分类Ionosphere电离层数据
文章目录 摘要1.数据获取2.数据集分割与初步训练表现3.测试不同近邻值4.交叉检验5. 十折交叉检验6.输出预测结果摘要本文使用python机器学习库Scikit-learn中的工具,以某网站电离层数据为案例,使用近邻算法进行分类预测。并在训练后使用K折交叉检验进行检验,最后输出预测结果及准确率。...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。


机器学习平台 PAI数据相关内容
- 机器学习平台 PAI训练数据
- 机器学习平台 PAI评估数据
- 机器学习平台 PAI代码数据
- 机器学习平台 PAI解码数据
- 机器学习平台 PAI鸢尾花数据
- 机器学习平台 PAI oss数据
- 机器学习平台 PAI pytorch压缩数据
- 机器学习平台 PAI数据字段
- 机器学习平台 PAI数据代码
- 开源机器学习平台 PAI平台数据
- 机器学习平台 PAI demo数据
- taurus机器学习平台 PAI数据架构
- 机器学习平台 PAI数据平衡
- 机器学习平台 PAI文本数据
- 机器学习平台 PAI数据特征预处理
- 机器学习平台 PAI数据特征
- 机器学习平台 PAI决策树数据
- 机器学习平台 PAI特征工程数据
- 机器学习平台 PAI结构化数据
- 数据机器学习平台 PAI
- 机器学习平台 PAI泰坦尼克数据
- 机器学习平台 PAI自然语言数据
- 合成数据机器学习平台 PAI
- 码农入门机器学习平台 PAI数据技能
- 机器学习平台 PAI实践数据代码
- 机器学习平台 PAI管理数据
- 大数据机器学习平台 PAI案例数据缓冲区
- 机器学习平台 PAI方法数据
- 机器学习平台 PAI数据科学统计学习数据
- 机器学习平台 PAI语言数据
- 机器学习平台 PAIr语言数据
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI论文
- 机器学习平台 PAI代码
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI构建
- 机器学习平台 PAI模型
- 机器学习平台 PAIpai
- 机器学习平台 PAI升级
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI分类
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI平台
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践