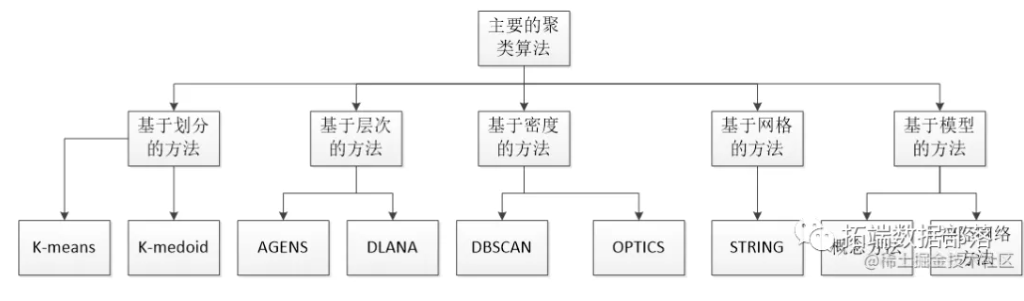
R语言K-Means(K均值聚类)和层次聚类算法对微博用户特征数据研究
全文链接:https://tecdat.cn/?p=32955 本文就将采用K-means算法和层次聚类对基于用户特征的微博数据帮助客户进行聚类分析(点击文末“阅读原文”获取完整代码数据)。 首先对聚类分析作系统介绍。其次对聚类算法进行文献回顾,对其概况、基本思想、算法进行详细介绍,再是通过对微博数...

数据分享|R语言改进的K-MEANS(K-均值)聚类算法分析股票盈利能力和可视化
全文链接:http://tecdat.cn/?p=32418 大量数据中具有"相似"特征的数据点或样本划分为一个类别。聚类分析提供了样本集在非监督模式下的类别划分(点击文末“阅读原文”获取完整代码数据)。 人们在投资时总期望以最小的风险获取最大的利益,面对庞大的股票市场和繁杂的股票数据,要想对股票进...


R语言K-Means(K-均值)聚类、朴素贝叶斯(Naive Bayes)模型分类可视化
全文链接:http://tecdat.cn/?p=32355 分类是把某个对象划分到某个具体的已经定义的类别当中,而聚类是把一些对象按照具体特征组织到若干个类别里(点击文末“阅读原文”获取完整代码数据)。 虽然都是把某个对象划分到某个类别中,但是分类的类别是已经预定义的,而聚类操作时,某个对象所属的...
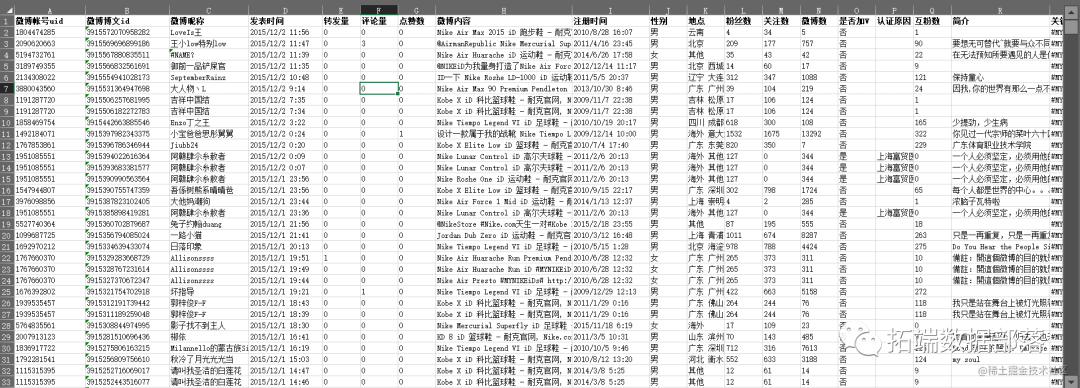
R语言对耐克NIKEID新浪微博数据K均值(K-MEANS)聚类文本挖掘和词云可视化
全文链接:http://tecdat.cn/?p=31048 2009年8月,新浪微博(micro-blog)开始服务,随后各家微博服务在国内得到广泛传播和应用"(点击文末“阅读原文”获取完整代码数据)。 微博具有文本信息短(140字包括标点符号)、词量少、裂变式传播、传播速度快、用词不规范等特征,...
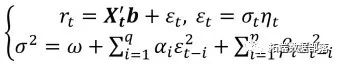
R语言预测期货波动率的实现:ARCH与HAR-RV与GARCH,ARFIMA模型比较
波动率是众多定价和风险模型中的关键参数,例如BS定价方法或风险价值的计算。在这个模型中,或者说在教科书中,这些模型中的波动率通常被认为是一个常数。然而,情况并非如此,根据学术研究,波动率是具有聚类,厚尾和长记忆特征的时间序列变量。 本博客比较了GARCH模型(描述波动率聚类),ARFIMA模型( 长...

R语言实现k-means聚类优化的分层抽样(Stratified Sampling)分析各市镇的人口
简介 假设我们需要设计一个抽样调查,有一个完整的框架,包含目标人群的信息(识别信息和辅助信息)。如果我们的样本设计是分层的,我们需要选择如何在总体中形成分层,以便从现有的辅助信息中获得最大的优势。 换句话说,我们必须决定以何种方式来组合辅助变量(从现在开始是 "X "变量)的值,来确定一个新的变量,...
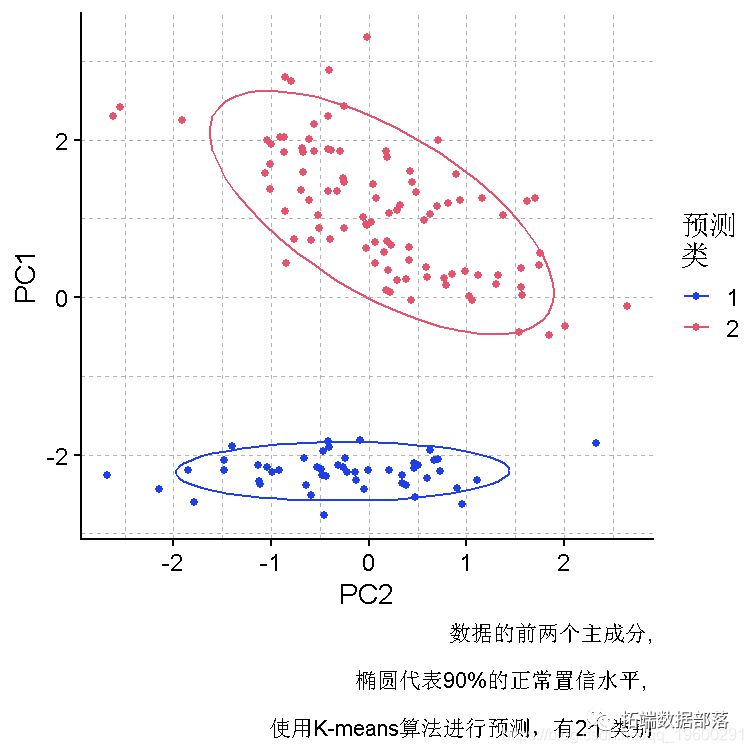
R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集
本练习问题包括:使用R中的鸢尾花数据集 (a)部分:k-means聚类 使用k-means聚类法将数据集聚成2组。 画一个图来显示聚类的情况 使用k-means聚类法将数据集聚成3组。 画一个图来显示聚类的情况 (b)部分:层次聚类 使用全连接法对观察值进行聚类。 使用平均和单连接对观测值进行聚类。...

r语言聚类分析:k-means和层次聚类
聚类分析算法很多,比较经典的有k-means和层次聚类法。 k-means聚类分析算法 k-means的k就是最终聚集的簇数,这个要你事先自己指定。k-means在常见的机器学习算法中算是相当简单的,基本过程如下: 首先任取k个样本点作为k个簇的初始中心; 对每一个样本点,计算它们与k个中心的距离,...
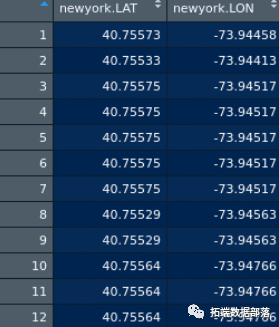
R语言使用K-Means聚类可视化WiFi访问
可视化已成为数据科学在电信行业中的关键应用。具体而言,电信分析高度依赖于地理空间数据的使用。 这是因为电信网络本身在地理上是分散的,并且对这种分散的分析可以产生关于网络结构,消费者需求和可用性的有价值的见解。 数据 为了说明这一点,使用k均值聚类算法来分析免费公共WiFi的地理数据。 具体地,k均值...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。