
数据分享|R语言聚类、文本挖掘分析虚假电商评论数据:K-MEANS(K-均值)、层次聚类、词云可视化
全文链接:http://tecdat.cn/?p=32540 聚类分析是一种常见的数据挖掘方法,已经广泛地应用在模式识别、图像处理分析、地理研究以及市场需求分析。本文主要研究聚类分析算法K-means在电商评论数据中的应用,挖掘出虚假的评论数据(点击文末“阅读原文”获取完整代码数据)。 本文主要帮助...
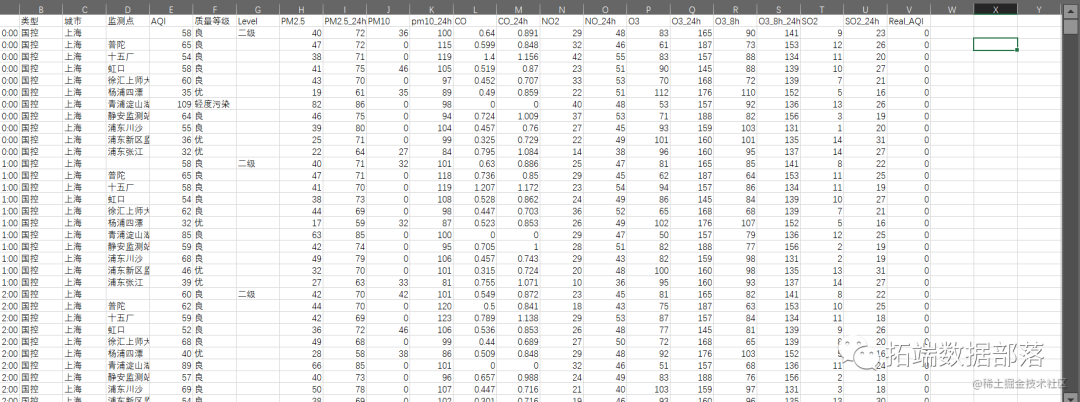
数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法
全文链接:http://tecdat.cn/?p=30131 最近我们被客户要求撰写关于上海空气质量指数的研究报告。本文向大家介绍R语言对上海PM2.5等空气质量数据(查看文末了解数据免费获取方式)间的相关分析和预测分析,主要内容包括其使用实例,具有一定的参考价值,需要的朋友可以参考一下(点击文末“...

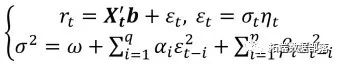
R语言预测期货波动率的实现:ARCH与HAR-RV与GARCH,ARFIMA模型比较
波动率是众多定价和风险模型中的关键参数,例如BS定价方法或风险价值的计算。在这个模型中,或者说在教科书中,这些模型中的波动率通常被认为是一个常数。然而,情况并非如此,根据学术研究,波动率是具有聚类,厚尾和长记忆特征的时间序列变量。 本博客比较了GARCH模型(描述波动率聚类),ARFIMA模型( 长...

R语言KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数
简介 《世界幸福报告》是可持续发展解决方案网络的年度报告,该报告使用盖洛普世界民意调查的调查结果研究了150多个国家/地区的生活质量。报告的重点是幸福的社交环境。在本项目中,我将使用世界幸福报告中的数据来探索亚洲22个国家或地区,并通过查看每个国家的阶梯得分,社会支持,健康的期望寿命,自由选择生活,...
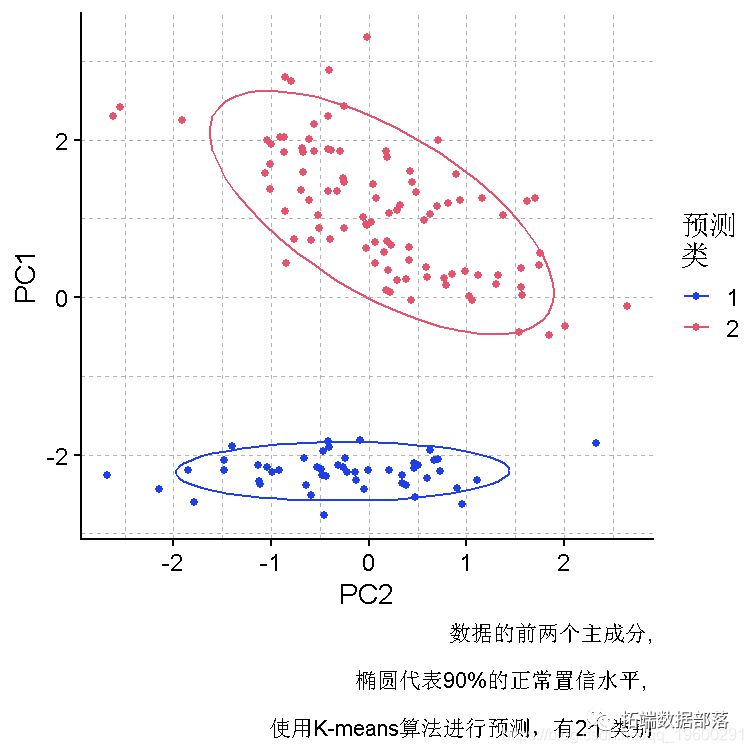
R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集
本练习问题包括:使用R中的鸢尾花数据集 (a)部分:k-means聚类 使用k-means聚类法将数据集聚成2组。 画一个图来显示聚类的情况 使用k-means聚类法将数据集聚成3组。 画一个图来显示聚类的情况 (b)部分:层次聚类 使用全连接法对观察值进行聚类。 使用平均和单连接对观测值进行聚类。...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。