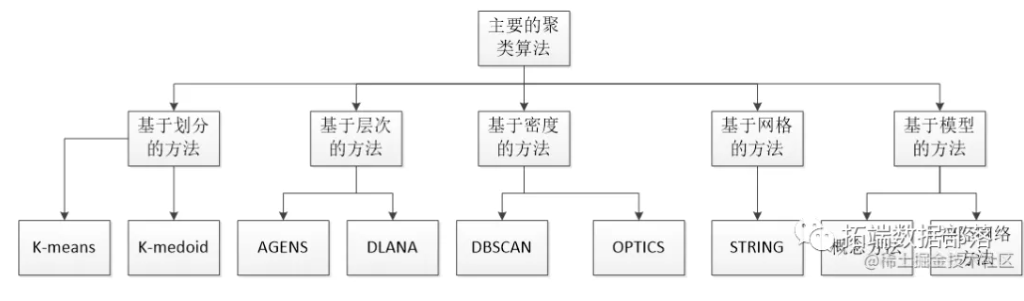
R语言K-Means(K均值聚类)和层次聚类算法对微博用户特征数据研究
全文链接:https://tecdat.cn/?p=32955 本文就将采用K-means算法和层次聚类对基于用户特征的微博数据帮助客户进行聚类分析(点击文末“阅读原文”获取完整代码数据)。 首先对聚类分析作系统介绍。其次对聚类算法进行文献回顾,对其概况、基本思想、算法进行详细介绍,再是通过对微博数...

数据分享|R语言改进的K-MEANS(K-均值)聚类算法分析股票盈利能力和可视化
全文链接:http://tecdat.cn/?p=32418 大量数据中具有"相似"特征的数据点或样本划分为一个类别。聚类分析提供了样本集在非监督模式下的类别划分(点击文末“阅读原文”获取完整代码数据)。 人们在投资时总期望以最小的风险获取最大的利益,面对庞大的股票市场和繁杂的股票数据,要想对股票进...


R语言K-Means(K-均值)聚类、朴素贝叶斯(Naive Bayes)模型分类可视化
全文链接:http://tecdat.cn/?p=32355 分类是把某个对象划分到某个具体的已经定义的类别当中,而聚类是把一些对象按照具体特征组织到若干个类别里(点击文末“阅读原文”获取完整代码数据)。 虽然都是把某个对象划分到某个类别中,但是分类的类别是已经预定义的,而聚类操作时,某个对象所属的...
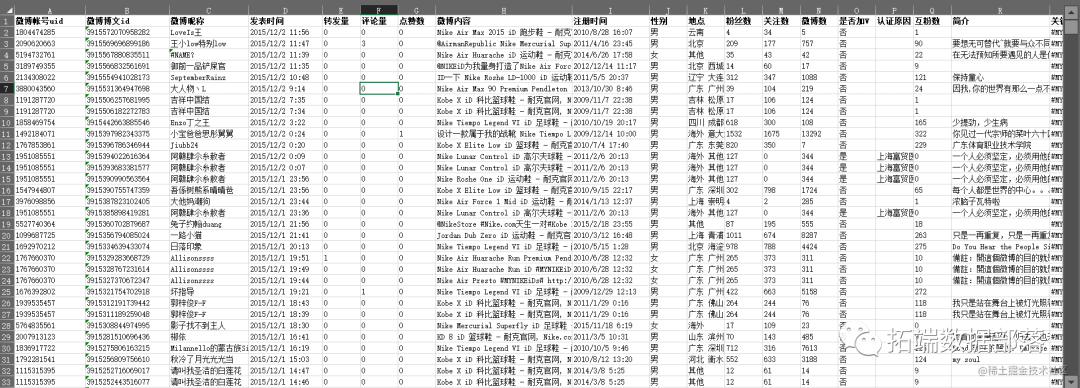
R语言对耐克NIKEID新浪微博数据K均值(K-MEANS)聚类文本挖掘和词云可视化
全文链接:http://tecdat.cn/?p=31048 2009年8月,新浪微博(micro-blog)开始服务,随后各家微博服务在国内得到广泛传播和应用"(点击文末“阅读原文”获取完整代码数据)。 微博具有文本信息短(140字包括标点符号)、词量少、裂变式传播、传播速度快、用词不规范等特征,...

R语言KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数
简介 《世界幸福报告》是可持续发展解决方案网络的年度报告,该报告使用盖洛普世界民意调查的调查结果研究了150多个国家/地区的生活质量。报告的重点是幸福的社交环境。在本项目中,我将使用世界幸福报告中的数据来探索亚洲22个国家或地区,并通过查看每个国家的阶梯得分,社会支持,健康的期望寿命,自由选择生活,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。