
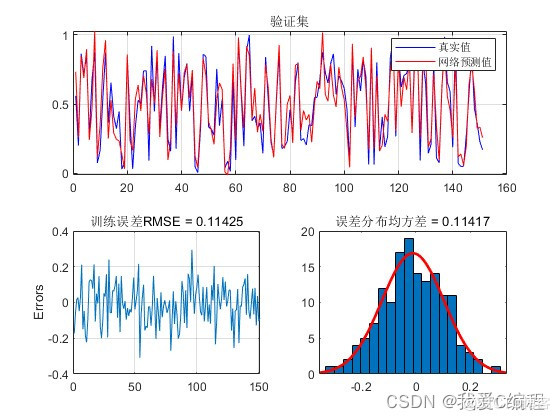
m基于GA-LSTM遗传优化长短期记忆网络的电力负荷数据预测算法matlab仿真
1.算法仿真效果matlab2022a仿真结果如下: 2.算法涉及理论知识概要 基于GA-LSTM遗传优化长短记忆网络的电力负荷数据预测算法是一种结合了遗传算法(GA)和长短时记忆网络(LSTM)的混合模型,用于预测电力负荷数据。该算法通过遗传算法优化LSTM模型的超参数,以提高模型的预测性能。下面...
m基于GMDH网络模型的数据训练和分类matlab仿真
1.算法仿真效果matlab2022a仿真结果如下: 2.算法涉及理论知识概要 GMDH神经网络的主要思想是由系统各输入单元交叉组合产生一系列的活动神经元, 其中每一神经元都具有选择最优传递函数的功能, 再从已产生的一代神经元中选择若干与目标变量最为接近的神经元, 被选出神经元强强结合再次产生新的神...
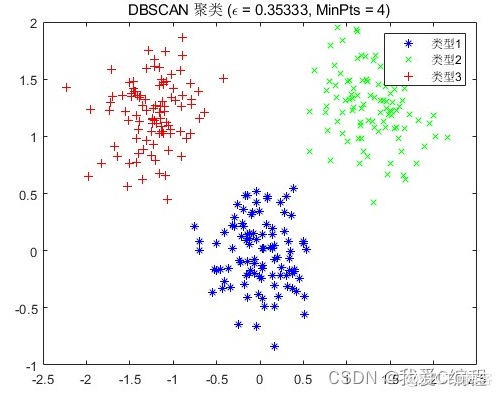
基于Multi-Verse Optimizer(MVO)多元宇宙优化的DBSCAN数据聚类算法matlab仿真
1.算法仿真效果matlab2022a仿真结果如下:2.算法涉及理论知识概要 2015年,S Mirjalili,SM Mirjalili和AHatamlou共同提出了一种基于物理学中多元宇宙理论的群智能优化算法——多元宇宙优化算法(Multi-Verse Optimizer,MVO),并成功将其应...
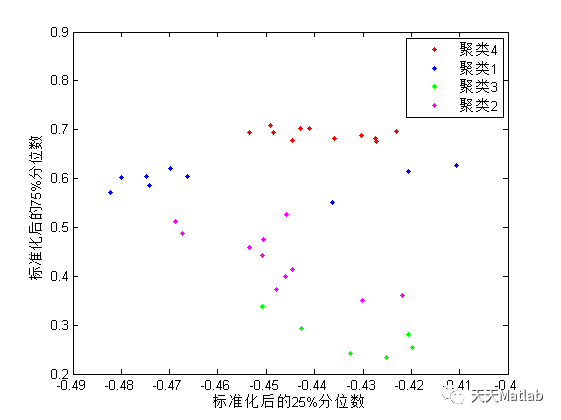
基于高斯混合和谱聚类实现数据聚类含计算轮廓系数评估附matlab仿真
✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。🍎个人主页:Matlab科研工作室🍊个人信条:格物致知。更多Matlab仿真内容点击👇智能优化算法 神经网络预测 雷...
基于小波变换的数据峰值检测matlab仿真
1.算法仿真效果matlab2022a仿真结果如下:2.算法涉及理论知识概要 小波变换(wavelet transform,WT)是一种新的变换分析方法,它继承和发展了短时傅立叶变换局部化的思想,同时又克服了窗口大小不随频率变化等缺点,能够提供一个随频率改变的“时间-频率”窗口,是进行信号时频分析和...

m基于多核学习支持向量机MKLSVM的数据预测分类算法matlab仿真
1.算法描述 20世纪60年代Vapnik等人提出了统计学习理论。基于该理论,于90年代给出了一种新的学习方法——支持向量机。该方法显著优点为根据结构风险最小化归纳准则,有效地避免了过学习、维数灾难和局部极小等传统机器学习中存在的弊端,且在小样本情况下仍然具有良好的泛化能力,从而该算法受到了广泛的关...
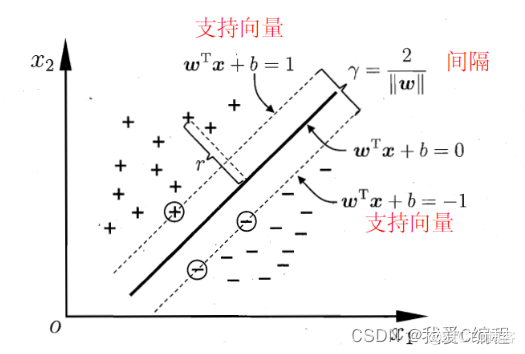
m基于分段蚁群算法优化SVM的数据预测matlab仿真
1.算法描述 支持向量机(support vector machines, SVM)是二分类算法,所谓二分类即把具有多个特性(属性)的数据分为两类,目前主流机器学习算法中,神经网络等其他机器学习模型已经能很好完成二分类、多分类,学习和研究SVM,理解SVM背后丰富算法知识,对以后研究其他算法大有裨益...
m基于果蝇优化的K-means数据聚类分析matlab仿真
1.算法描述 果蝇优化算法FOA(Fruit Fly Optimization Algorithm)是由台湾博士潘文超于2011年提出的,与蚁群算法和粒子群算法类似,是基于动物群体觅食行为演化出的一种寻求全局优化的新方法[1-3]。它不同于顺序执行的传统智能算法,而是以果蝇群体自组织性和并行性为基础...
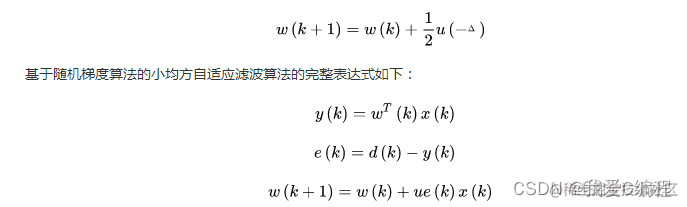
基于LS最小二乘法的数据拟合matlab仿真
1.算法描述 最小均方算法,简称LMS算法,是一种最陡下降算法的改进算法, 是在维纳滤波理论上运用速下降法后的优化延伸,最早是由 Widrow 和 Hoff 提出来的。 该算法不需要已知输入信号和期望信号的统计特征,“当前时刻”的权系数是通过“上一 时刻”权系数再加上一个负均方误差梯度的比例项求得。...

m基于kmeans和SVM的网络入侵数据分类算法matlab仿真
1.算法描述 首先计算整个数据集合的平均值点,作为第一个初始聚类中心C1; 然后分别计算所有对象到C1的欧式距离d,并且计算每个对象在半径R的范围内包含的对象个数W。 此时计算P=u*d+(1-u)*W,所得到的最大的P值所对应的的对象作为第二个初始聚类中心C2。 同样的方法,分别计算所有对象到C2...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



MATLAB仿真相关内容
- MATLAB仿真gui
- 检测系统MATLAB仿真gui界面
- 检测MATLAB仿真gui界面
- 深度学习系统MATLAB仿真gui界面
- yolov2 MATLAB仿真gui界面
- 深度学习MATLAB仿真
- 行为MATLAB仿真gui界面
- 行为系统MATLAB仿真
- yolov2深度学习系统MATLAB仿真
- 网络MATLAB仿真
- yolov2深度学习网络行为MATLAB仿真
- 网络MATLAB仿真gui界面
- yolov2行为MATLAB仿真
- 行为MATLAB仿真
- 人体MATLAB仿真
- 深度学习系统MATLAB仿真gui
- 深度学习行为系统MATLAB仿真
- 行为MATLAB仿真gui
- yolov2深度学习MATLAB仿真
- 深度学习系统MATLAB仿真
- 深度学习MATLAB仿真gui界面
- 系统MATLAB仿真界面
- 系统MATLAB仿真
- pso优化MATLAB仿真
- 序列MATLAB仿真
- lstm MATLAB仿真
- pso MATLAB仿真
- cnn MATLAB仿真
- 扩频水印嵌入MATLAB仿真
- 扩频MATLAB仿真
- dct MATLAB仿真
- 嵌入MATLAB仿真
- 雷达函数MATLAB仿真
- 雷达MATLAB仿真
- 函数MATLAB仿真
- 检测MATLAB仿真
- ofdm MATLAB仿真
- 学习MATLAB仿真
- 信道MATLAB仿真
- 编码MATLAB仿真
- 编码译码MATLAB仿真
- 调制MATLAB仿真
- 传输MATLAB仿真
- cnn-gru-attention回归预测MATLAB仿真
- ga优化MATLAB仿真
- ga MATLAB仿真
- 通信MATLAB仿真
- 通信链路MATLAB仿真
- scma MATLAB仿真
MATLAB更多仿真相关
- 仿真MATLAB
- MATLAB误码率仿真
- 三维MATLAB仿真
- 遗传优化算法MATLAB仿真
- ga遗传优化MATLAB仿真
- 变换MATLAB仿真
- 通信系统MATLAB仿真
- 深度学习检测MATLAB仿真
- 神经网络算法MATLAB仿真
- 编译码MATLAB仿真
- 识别MATLAB仿真
- bp MATLAB仿真
- 误码率MATLAB仿真
- MATLAB系统仿真
- 链路MATLAB仿真
- qpsk MATLAB仿真
- 人脸MATLAB仿真
- 自适应MATLAB仿真
- 特征提取MATLAB仿真
- 形态学MATLAB仿真
- 模型MATLAB仿真
- MATLAB仿真分析
- 解调MATLAB仿真
- MATLAB simulink仿真
- 估计MATLAB仿真
- 二维MATLAB仿真
- 数据预测MATLAB仿真
- 目标MATLAB仿真
- MATLAB仿真qpsk
- qam MATLAB仿真
- 信息MATLAB仿真
- 技术MATLAB仿真
- grnn MATLAB仿真
- mimo MATLAB仿真
- 优化系统MATLAB仿真
- ldpc编译码MATLAB仿真
- 车辆MATLAB仿真
- 特征提取算法MATLAB仿真
- 深度学习网络系统MATLAB仿真gui
- 性能MATLAB仿真
- 参数MATLAB仿真
- 避障MATLAB仿真
- 路线MATLAB仿真
- svm MATLAB仿真
- 相位MATLAB仿真
- r-cnn MATLAB仿真
- 小波变换MATLAB仿真
- 调制解调系统MATLAB仿真
- 建模MATLAB仿真
- 粒子群MATLAB仿真