[帮助文档] 迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
[帮助文档] 基于Hadoop集群支持Delta Lake或Hudi存储机制
Delta Lake和Hudi是数据湖方案中常用的存储机制,为数据湖提供流处理、批处理能力。MaxCompute基于开源的Hadoop集群提供了支持Delta或Hudi存储机制的湖仓一体架构。您可以通过MaxCompute查询到实时数据,即时洞察业务数据变化。


大数据面试题百日更新_Hadoop专题(Day10)
12. 请说下 MR 中 shuffle 阶段13. shuffle 阶段的数据压缩机制了解吗
大数据面试题百日更新_Hadoop专题(Day09)
10. 请说下 MR 中 Map Task 的工作机制简单概述:inputFile 通过 split 被切割为多个 split 文件,通过 Record 按行读取内容给map(自己写的处理逻辑的方法),数据被 map 处理完之后交给 OutputCollect 收集器,对其结果 key 进行分区(默...

大数据面试题百日更新_Hadoop专题(Day08)
请说下 HDFS 的组织架构

大数据面试题百日更新_Hadoop专题(Day06)
大数据面试题百日更新_Hadoop专题(Day06)在 NameNode HA 中,会出现脑裂问题吗?怎么解决脑裂

大数据面试题百日更新_Hadoop专题(Day05)
6. Secondary NameNode 不能恢复 NameNode 的全部数据,那如何 保证 NameNode 数据存储安全
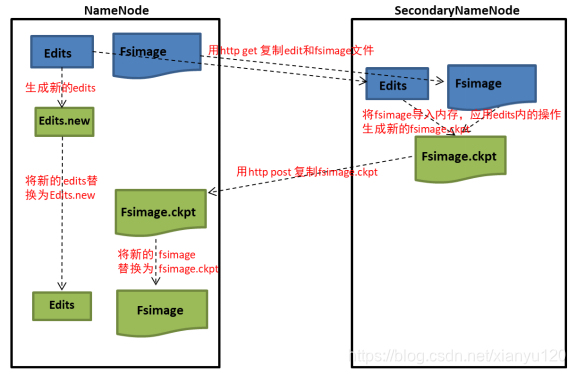
大数据面试题百日更新_Hadoop专题(Day04)
5. Secondary NameNode 了解吗,它的工作机制是怎样的Secondary NameNode 是合并 NameNode 的 edit logs 到 fsimage 文件中; 它的具体工作机制:(1)Secondary NameNode 询问 NameNode 是否需要 checkpo...

大数据面试题百日更新_Hadoop专题(Day03)
4. NameNode 在启动的时候会做哪些操作
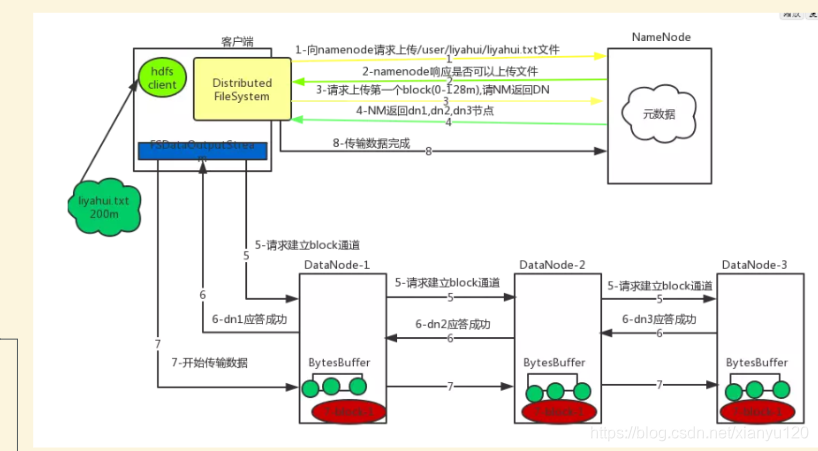
大数据面试题百日更新_Hadoop专题(Day01)
Hadoophadoop 中常问的有三块,第一:存储,问到存储,就把 HDFS 相关的知识点拿出来;第二:计算框架(MapReduce);第三:资源调度框架(yarn)请说下 HDFS 读写流程 这个问题虽然见过无数次,面试官问过无数次,但是就是有人不能完整的说下来,所以 请务必记住。并且很多问题都...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









hadoop大数据相关内容
- 大数据技术hadoop
- 大数据hadoop分布式
- 大数据hadoop
- 大数据hadoop部署
- 大数据hadoop配置
- 大数据hadoop spark安装
- 大数据hadoop实战源码
- 大数据hadoop运行
- 大数据hadoop机制
- 大数据hadoop单词源码
- 大数据hadoop mapreduce
- 大数据hadoop编程
- 大数据hadoop pdf
- 大数据spark企业级hadoop pdf ppt
- 大数据hadoop技术
- 大数据hadoop spark flink
- 大数据处理hadoop大数据
- hadoop大数据编程模型
- hadoop大数据原理
- 大数据框架hadoop
- hadoop分布式大数据
- 大数据hadoop运行环境
- 大数据hadoop ha
- 大数据hadoop集群搭建
- 大数据hadoop实战篇
- hadoop小菜大数据
- 大数据hadoop源代码
- 大数据hadoop ubuntu
- 大数据hadoop端口
- 六六大数据hadoop
- 大数据入门hadoop
- 大数据hadoop环境搭建
- hadoop大数据基础教程
- 数据平台hadoop大数据
- hadoop大数据工具
- hadoop大数据计算存储服务平台
- 大数据hadoop大数据平台
- 大数据hadoop开发
- hadoop大数据应用
- 大数据hadoop家族
- 大数据hadoop方法
- hadoop大数据开源工具
- 大数据安全hadoop
- 大数据原理hadoop
- 大数据框架hadoop spark
- hadoop大数据价值
- 大数据apache hadoop概述
- hadoop cutting大数据