[帮助文档] 如何在MaxCompute中如何创建外部项目,并查询Hadoop中的表数据
本文以E-MapReduce的Hive为例,为您介绍在MaxCompute中如何创建外部项目,并查询Hadoop中的表数据。
[帮助文档] 迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。

[帮助文档] 基于Hadoop集群支持Delta Lake或Hudi存储机制
Delta Lake和Hudi是数据湖方案中常用的存储机制,为数据湖提供流处理、批处理能力。MaxCompute基于开源的Hadoop集群提供了支持Delta或Hudi存储机制的湖仓一体架构。您可以通过MaxCompute查询到实时数据,即时洞察业务数据变化。
[帮助文档] 如何通过MaxCompute与Hadoop构建湖仓一体
通过MaxCompute与Hadoop构建湖仓一体方案旨在实现对海量数据的统一管理、存储和分析,提供了一个既能处理结构化、半结构化数据,又能满足高并发分析需求的一体化数据平台。本文为您介绍如何通过MaxCompute与Hadoop构建湖仓一体,以及管理湖仓一体项目。
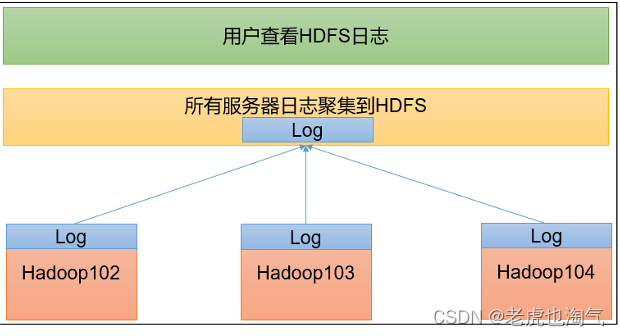
Hadoop学习指南:探索大数据时代的重要组成——Hadoop运行模式(下)
前言接着上篇,我们继续学习Hadoop运行模式。2.6 配置历史服务器为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:1)配置mapred-site.xml[atguigu在该文件里面增加如下配置。<!-- 历史服务器端地址 --> <property>...
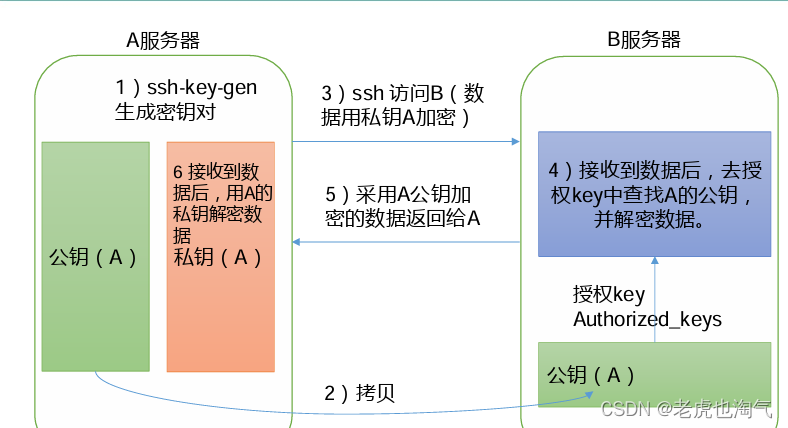
Hadoop学习指南:探索大数据时代的重要组成——Hadoop运行模式(上)
前言今天我们具体来介绍一下Hadoop的运行模式具体内容移步正文。Hadoop运行模式1)Hadoop 官方网站:http://hadoop.apache.org/2)Hadoop 运行模式包括:本地模式、伪分布式模式以及完全分布式模式。➢ 本地模式:单机运行,只是用来演示一下官方案例。==生产环....
[帮助文档] 如何管理SmartDataHadoop回收站
Hadoop回收站是Hadoop文件系统的重要功能,可以恢复误删除的文件和目录。本文为您介绍Hadoop回收站的使用方法。
Hadoop大数据平台实战(05):深入Spark Cluster集群模式YARN vs Mesos vs Standalone vs K8s
Spark可以以分布式集群架构模式运行,如果我们不熟Spark Cluster,这个时候需要集群管理器帮助我们管理Spark 集群。 集群管理器根据需要为所有工作节点提供资源,操作所有节点。负责管理和协调集群节点的程序一般叫做:Cluster Manager,集群管理器。目前搭建Spark 集群,可...
Hadoop大数据平台实战(00):Linux Ubuntu 18.04实战安装大数据Hadoop 3.1.2版本 单节点模式
Linux Ubuntu 18.04实战安装大数据Hadoop 3.1.2版本。这里分别选择最新的Ubuntu系统 18.04,以及最新的Hadoop版本3.1.2Hadoop是开源免费的大数据方案,官方网站https://hadoop.apache.org/,核心的组件都是使用Java开发,也是目...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









hadoop大数据相关内容
- 大数据hadoop编程
- 大数据hadoop mapreduce
- 大数据hadoop案例
- 大数据实战hadoop
- 大数据hadoop实践
- 大数据hadoop mapreduce编程
- 大数据hadoop
- 大数据技术hadoop
- 大数据hadoop分布式
- 大数据hadoop分布式计算
- apache hadoop分布式大数据
- hadoop分布式大数据
- hadoop分布式大数据平台
- apache hadoop大数据
- 大数据hadoop spark java
- 大数据面试hadoop
- 大数据面试题百日hadoop
- 大数据hadoop部署
- 大数据hadoop配置
- 大数据hadoop原理
- 大数据hadoop spark安装
- 大数据hadoop实战源码
- 大数据hadoop spark rdd
- 大数据hadoop运行
- 大数据hadoop机制
- 大数据hadoop单词源码
- 大数据技术hadoop spark mapreduce
- 大数据hadoop pdf
- 大数据spark企业级hadoop pdf ppt
- 大数据hadoop技术
- 大数据部署hadoop
- 大数据hadoop spark flink
- 大数据处理hadoop大数据
- hadoop大数据编程模型
- hadoop大数据原理
- 大数据框架hadoop
- 大数据hadoop运行环境
- 大数据环境hadoop安装
- hadoop大数据zookeeper
- 大数据hadoop ha
- 大数据hadoop集群搭建
- 大数据hadoop实战篇
- hadoop小菜大数据
- 大数据hadoop源代码
- 大数据原理hadoop
- 大数据hadoop ubuntu
- 大数据伪分布hadoop步骤
- 构建大数据hadoop
hadoop更多大数据相关
- hadoop大数据工具
- 大数据分析hadoop
- hadoop大数据应用
- 大数据框架hadoop spark
- hadoop大数据数据
- 大数据hadoop开发
- 大数据入门hadoop
- hadoop cutting大数据
- 大数据hadoop系统安装
- hadoop大数据开源工具
- 大数据hadoop家族
- 大数据hadoop大数据平台
- 大数据hadoop方法
- 六六大数据hadoop
- 大数据安全hadoop
- 大数据大数据处理编程实践hadoop系统简介
- 大数据hadoop端口
- 大数据hadoop环境搭建
- 大数据hadoop环境配置
- hadoop大数据计算存储服务平台
- 大数据单机hadoop
- 数据平台hadoop大数据
- hadoop大数据基础教程
- 大数据apache hadoop概述
- hadoop海量数据处理技术项目实战大数据
- hadoop大数据价值
- 大数据hadoop产品