大数据Spark RDD持久化和Checkpoint
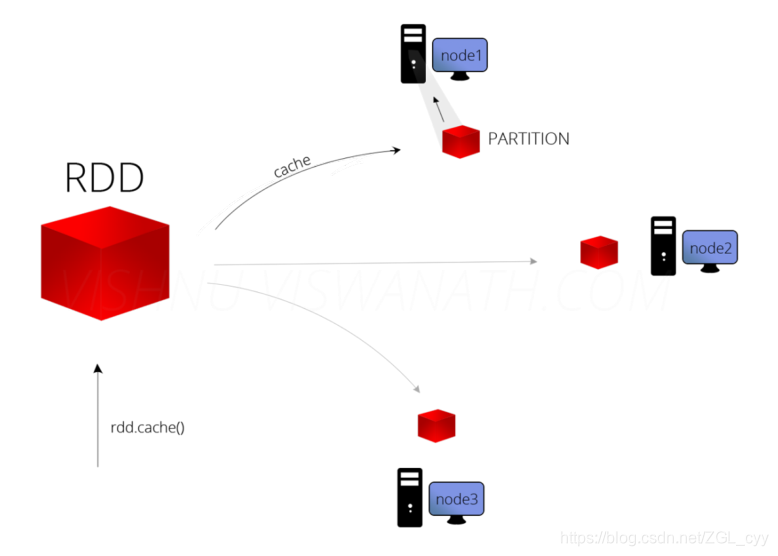
1 缓存函数在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。可以将RDD数据直接缓存到内存中,函数声明如下:但是实际项目中,不会直接使用上述的缓存函数&a...

大数据Spark RDD 函数 2
4.4 聚合函数在数据分析领域中,对数据聚合操作是最为关键的,在Spark框架中各个模块使用时,主要就是其中聚合函数的使用。4.4.1 集合中聚合函数回顾列表List中reduce聚合函数核心概念:聚合的时候,往往需要聚合中间临时变量。查看列表List中聚合函数reduce和fold源码如下:通过代...

大数据Spark RDD 函数 1
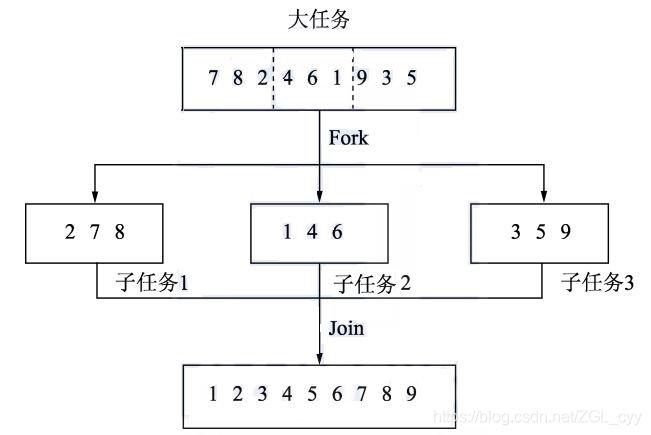
1 函数分类有一定开发经验的读者应该都使用过多线程,利用多核 CPU 的并行能力来加快运算速率。在开发并行程序时,可以利用类似 Fork/Join 的框架将一个大的任务切分成细小的任务,每个小任务模块之间是相互独立的,可以并行执行,然后将所有小任务的结果汇总起来,得到最终的结果。一个非常好的例子便是...

大数据Spark RDD介绍
1 RDD 定义对于大量的数据,Spark 在内部保存计算的时候,都是用一种叫做弹性分布式数据集(ResilientDistributed Datasets,RDD)的数据结构来保存的,所有的运算以及操作都建立在 RDD 数据结构的基础之上。在Spark开山之作Resilient Distribut...
[帮助文档] 如何使用SparkRDDAPI开发离线作业
本文介绍Spark如何访问SLS。
[帮助文档] 如何在使用SparkShell和RDD(新)_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
本文为您介绍如何使用Spark Shell,以及RDD的基础操作。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache sparkrdd相关内容
- apache spark学习rdd依赖持久化
- apache spark rdd依赖
- apache spark RDD持久化
- apache spark编程rdd分区action
- apache spark rdd算子
- apache spark学习RDD算子
- apache spark rdd分区规则
- apache spark rdd action
- apache spark学习rdd分区
- apache spark学习rdd
- apache spark rdd概述
- apache spark rdd分区
- apache spark rdd分区优化
- apache spark RDD操作
- apache spark精进rdd算子
- apache spark RDD编程
- apache spark rdd dataframe区别
- apache spark rdd属性
- apache spark rdd学习笔记
- apache spark原理逻辑图rdd学习笔记
- apache spark初次学习rdd笔记
- apache spark rdd学习
- apache spark rdd hdfs
- apache spark rdd特点
- apache spark rdd动态
- apache spark rdd函数
- apache spark rdd方法
- apache spark rdd应用
- apache spark rdd实操教程
- apache spark rdd容错
- apache spark rdd作用是什么
- apache spark rdd方法作用是什么
- apache spark rdd func方法作用是什么
- apache spark rdd saveastextfile
- apache spark rdd collect作用是什么
- apache spark rdd关系
- apache spark rdd弹性
- apache spark rdd怎么做
- apache spark RDD特性
- apache spark RDD依赖关系
- apache spark rdd依赖窄依赖
- apache spark RDD弹性分布式数据集
- apache spark读取rdd
- apache spark rdd scala
- apache spark rdd core
- apache spark key rdd
- apache spark rdd概念学习
- apache spark rdd概念学习算子
apache spark更多rdd相关
apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作