Spark学习--day04、RDD依赖关系、RDD持久化、RDD分区器、RDD文件读取与保存
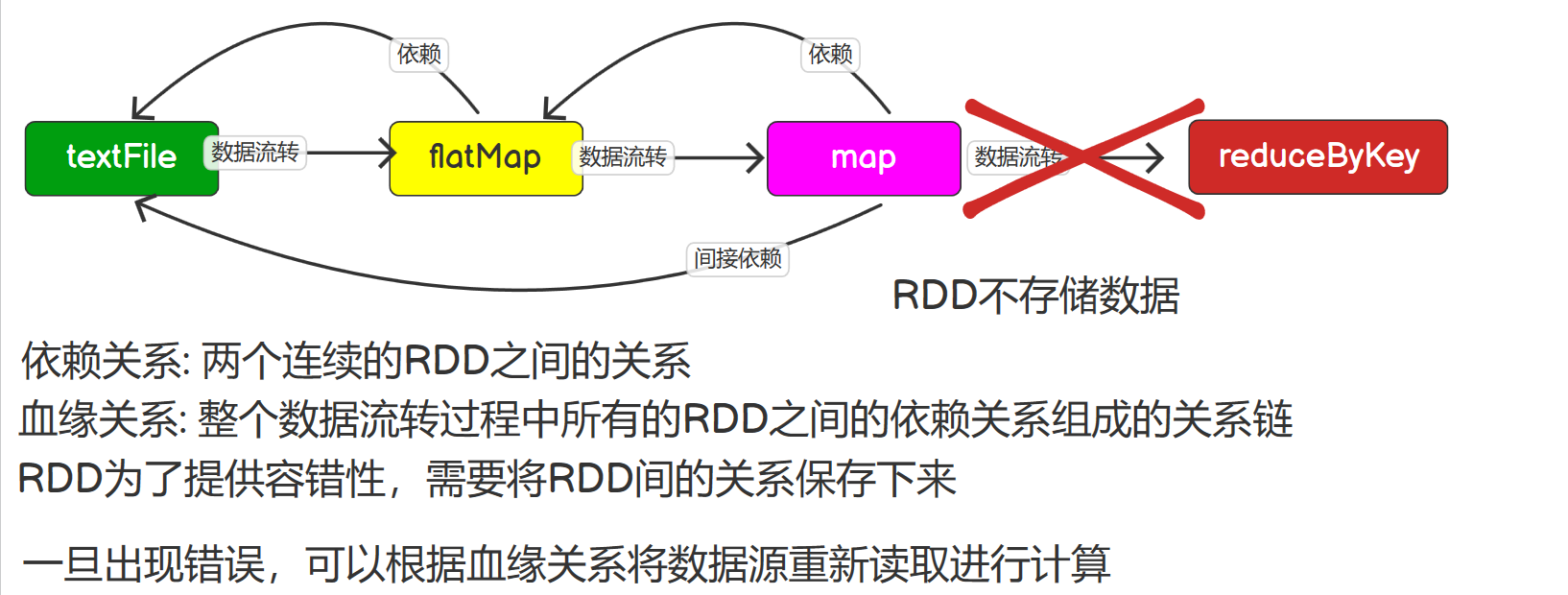
RDD依赖关系 查看血缘关系 RDD只支持粗粒度转换,每一个转换操作都是对上游RDD的元素执行函数f得到一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系。 将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,...
Spark RDD持久化与缓存:提高性能的关键
在大规模数据处理中,性能是至关重要的。Apache Spark是一个强大的分布式计算框架,但在处理大数据集时,仍然需要优化性能以获得快速的查询和分析结果。在本文中,将探讨Spark中的RDD持久化与缓存,这是提高性能的关键概念。 什么是RDD持久化与缓存? 在Spark中,RDD(弹性分布式数据集)...

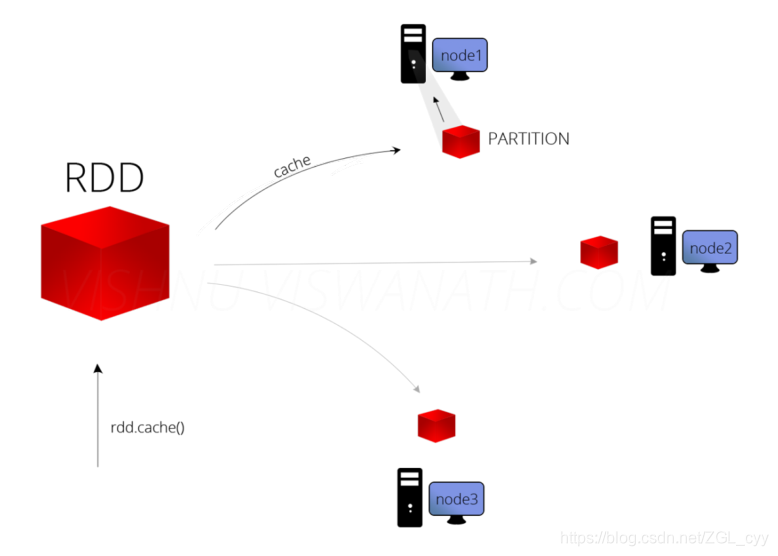
大数据Spark RDD持久化和Checkpoint
1 缓存函数在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。可以将RDD数据直接缓存到内存中,函数声明如下:但是实际项目中,不会直接使用上述的缓存函数&a...
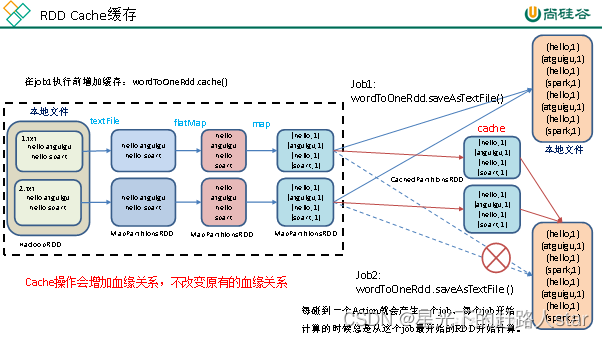
Spark学习--3、WordCount案例、RDD序列化、RDD依赖关系、RDD持久化(二)
4、RDD持久化4.1 RDD Cache缓存1、RDD Cache缓存(1)RDD通过Cache或者persist方法将前面的计算结果缓存(2)默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。(3)但是并不是这个两个方法被调用时立即缓存,而是触发后面的action算子时,该R...
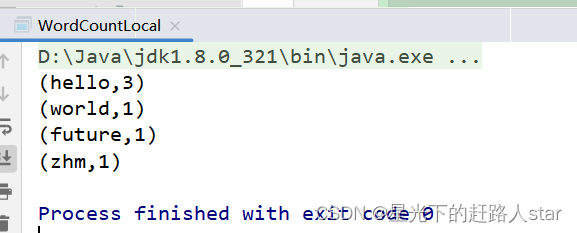
Spark学习--3、WordCount案例、RDD序列化、RDD依赖关系、RDD持久化(一)
1、WordCount案例实操导入项目依赖<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</art...
Spark RDD持久化的三种方式
前言在RDD中是不存储数据的,如果一个RDD需要重复使用,只是这个RDD对象是可以重用的,但是数据无法重用,那么需要从头再次执行来获取数据进行计算。Spark为了避免这种重复计算的情况,实现了RDD持久化功能。在Spark中,RDD的持久化算子有三个:cache、persist和checkpoint...
[帮助文档] 如何在使用SparkShell和RDD(新)_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
本文为您介绍如何使用Spark Shell,以及RDD的基础操作。

Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(下)
3. 持久化持久化,也就是将 RDD 的数据缓存到内存中/磁盘中,以后无论对这个RDD做多少次计算,都是直接取这个RDD的持久化的数据,比如从内存中或者磁盘中,直接提取一份数据。可以使用 persist()函数来进行持久化,一般默认的存储空间是在内存中,如果内存不够就会写入磁盘中。persist 持...
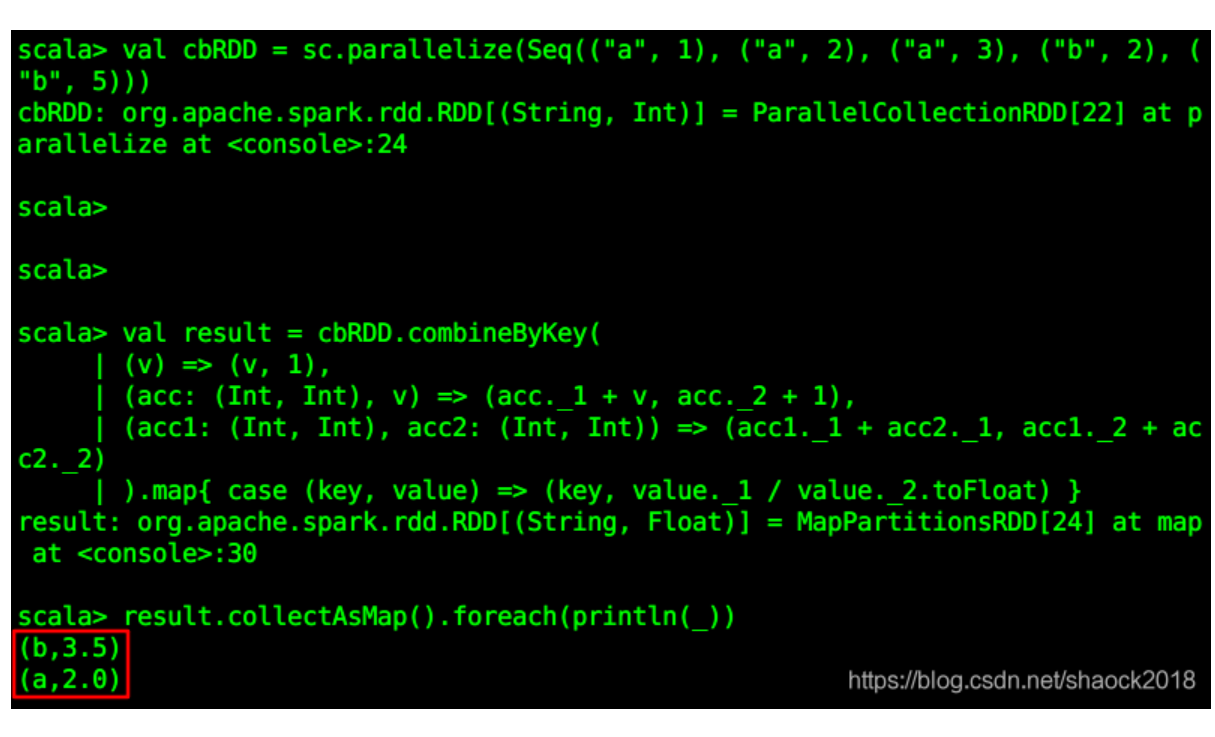
Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(中)
请看下面的例子(根据相同键,计算其所有值的平均值):val cbRDD = sc.parallelize(Seq(("a", 1), ("a", 2), ("a", 3), ("b", 2), ("b", 5)))val result = cbR...

Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(上)
0x00 教程内容转换算子与行动算子的进阶操作RDD的缓存与持久化0x01 进阶算子操作1. 创建RDDval rdd = sc.parallelize(List((1,1),(2,1),(3,1),(3,4)))2. 转换算子【1】reduceByKey(func)含义:合并具有相同键的值。rdd...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多rdd相关
- apache spark学习rdd依赖持久化
- apache spark rdd依赖
- apache spark编程rdd分区action
- apache spark rdd算子
- apache spark学习RDD算子
- apache spark rdd分区规则
- apache spark rdd action
- apache spark学习rdd分区
- apache spark rdd方法
- apache spark rdd学习
- apache spark rdd概念学习
- apache spark rdd作用是什么
- apache spark学习rdd
- apache spark RDD编程
- apache spark RDD操作
- apache spark rdd方法作用是什么
- apache spark rdd分区
- apache spark rdd概述
- apache spark rdd容错
- apache spark rdd func方法作用是什么
- apache spark rdd实战
- apache spark RDD特性
- apache spark rdd flatmap
- apache spark精进rdd算子
- 大数据apache spark rdd
- apache spark rdd core
- apache spark rdd特点
- apache spark rdd关系
- apache spark初次学习rdd笔记
- apache spark rdd弹性
- apache spark rdd学习笔记
- apache spark rdd saveastextfile
- apache spark rdd map
- apache spark RDD依赖关系
- apache spark rdd属性
- apache spark rdd dataframe区别
- apache spark rdd scala
- apache spark rdd应用
- apache spark rdd依赖窄依赖
- apache spark rdd实操教程
- apache spark rdd分区优化
- apache spark rdd阅读
- apache spark RDD弹性分布式数据集
- apache spark rdd函数
- apache spark rdd动态
- apache spark rdd怎么做
- apache spark rdd概念学习算子
- apache spark rdd hdfs
- apache spark key rdd
- apache spark rdd依赖宽依赖
apache spark您可能感兴趣
- apache spark可视化分析
- apache spark决策
- apache spark可视化
- apache spark分析
- apache spark Mapreduce
- apache spark SQL
- apache spark Python
- apache spark数据
- apache spark决策树
- apache spark资源消耗
- apache spark streaming
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark大数据分析