
Spark【Spark学习大纲】简介+生态+RDD+安装+使用(xmind分享)
Spark学习大纲 自学阶段整理的xmind思维导图分享。
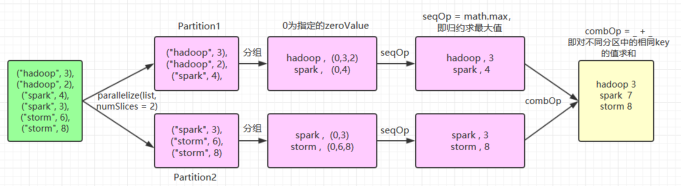
Spark【基础知识 03】【RDD常用算子详解】(图片来源于网络)
如果你是Java开发,还使用过 jdk1.8 的 storm 算子,RDD的常用算子理解起来就不难了。 1.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原RDD中每个元...

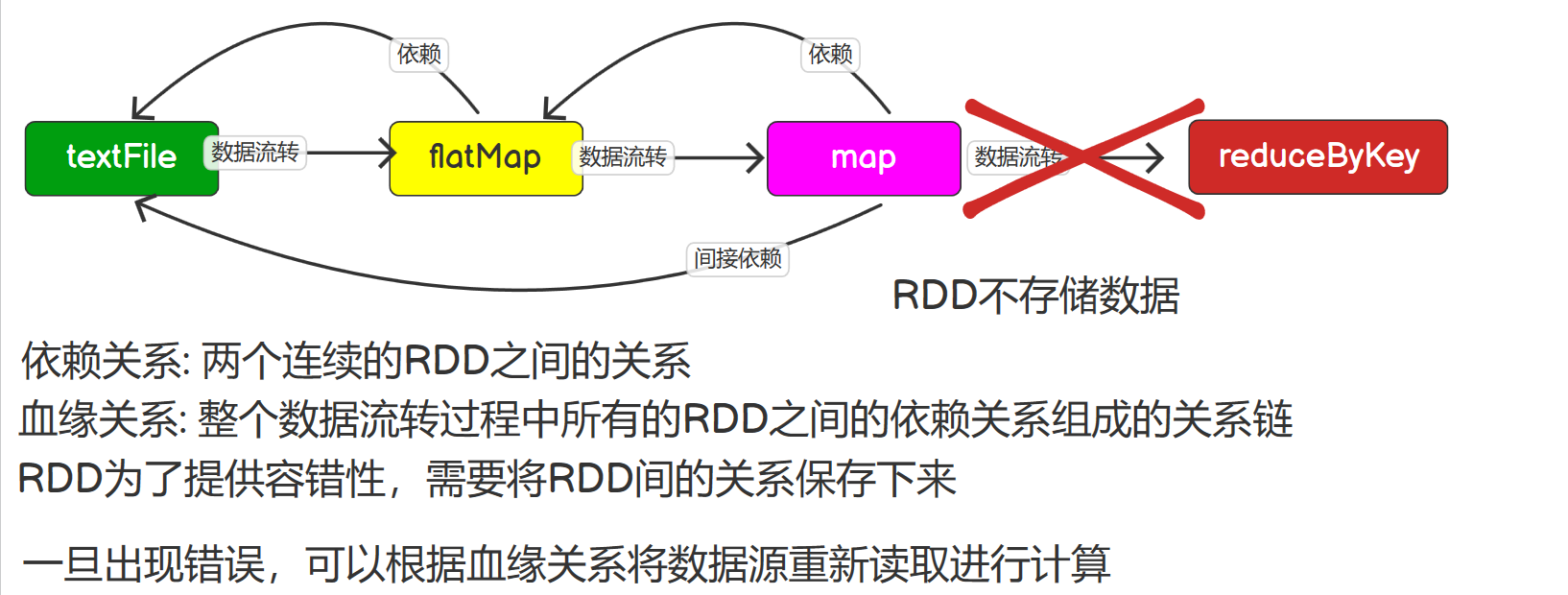
Spark学习--day04、RDD依赖关系、RDD持久化、RDD分区器、RDD文件读取与保存
RDD依赖关系 查看血缘关系 RDD只支持粗粒度转换,每一个转换操作都是对上游RDD的元素执行函数f得到一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系。 将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,...

Spark学习---day03、Spark核心编程(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(二)
Action行动算子 行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。 创建包名:com.zhm.spark.operator.action 1)reduce 聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据 packa...
Spark学习---day02、Spark核心编程(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(一)
Spark学习---day02、Spark核心编程(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(一)
Spark学习---day02、Spark核心编程(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(一)
前言 Spark计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是: RDD : 弹性分布式数据集 累加器:分布式共享只写变量 广播变量:分布式共享只读变量 接下...
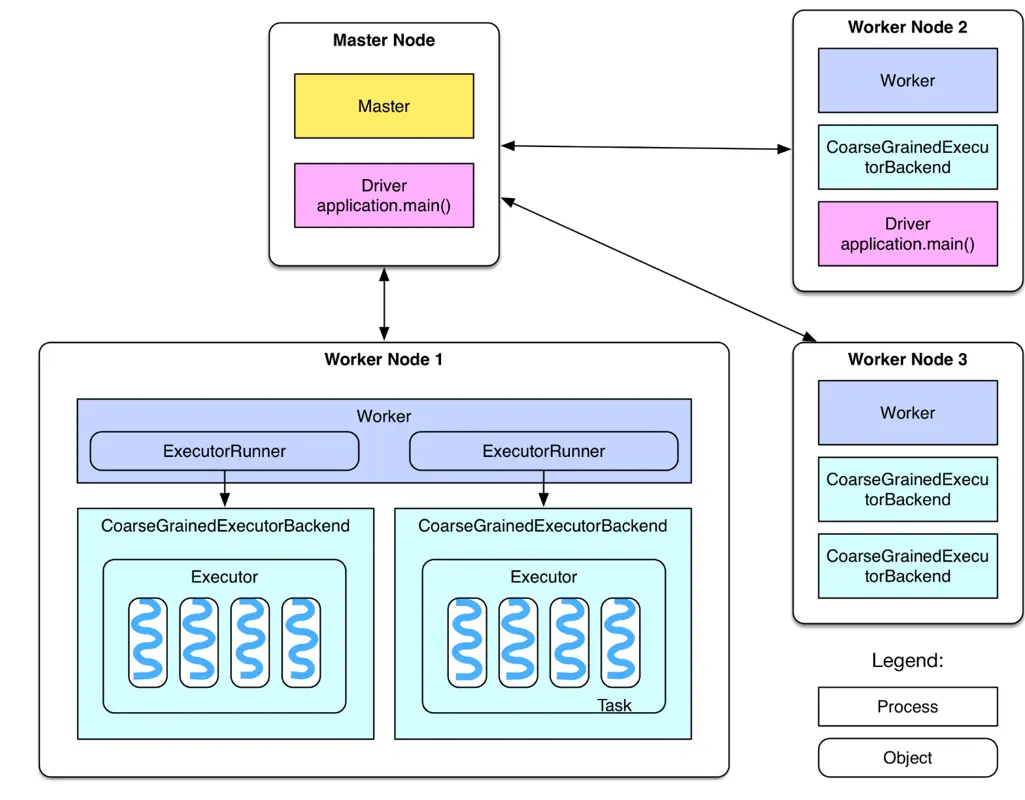
Spark 大数据实战:基于 RDD 的大数据处理分析
之前笔者参加了公司内部举办的一个 Big Data Workshop,接触了一些 Spark 的皮毛,后来在工作中陆陆续续又学习了一些 Spark 的实战知识。本文笔者从小白的视角出发,给大家普及 Spark 的应用知识。什么是 SparkSpark 集群是基于 Apache Spark 的分布式计...
Spark RDD操作性能优化技巧
Apache Spark是一个强大的分布式计算框架,用于处理大规模数据。然而,在处理大数据集时,性能优化成为一个关键问题。本文将介绍一些Spark RDD操作的性能优化技巧,帮助大家充分利用Spark的潜力,并获得更快的处理速度。 使用宽依赖操作时谨慎 在Spark中,每个RDD都有一个依赖关系图,...

Spark RDD分区和数据分布:优化大数据处理
在大规模数据处理中,Spark是一个强大的工具,但要确保性能达到最优,需要深入了解RDD分区和数据分布。本文将深入探讨什么是Spark RDD分区,以及如何优化数据分布以提高Spark应用程序的性能。 什么是RDD分区? 在Spark中,RDD(弹性分布式数据集)是数据处理的核心抽象,而RDD的分区...
Spark RDD持久化与缓存:提高性能的关键
在大规模数据处理中,性能是至关重要的。Apache Spark是一个强大的分布式计算框架,但在处理大数据集时,仍然需要优化性能以获得快速的查询和分析结果。在本文中,将探讨Spark中的RDD持久化与缓存,这是提高性能的关键概念。 什么是RDD持久化与缓存? 在Spark中,RDD(弹性分布式数据集)...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多rdd相关
- apache spark学习rdd依赖持久化
- apache spark rdd依赖
- apache spark RDD持久化
- apache spark编程rdd分区action
- apache spark rdd算子
- apache spark学习RDD算子
- apache spark rdd分区规则
- apache spark rdd action
- apache spark学习rdd分区
- apache spark rdd方法
- apache spark rdd学习
- apache spark rdd作用是什么
- apache spark学习rdd
- apache spark rdd概念学习
- apache spark RDD编程
- apache spark RDD操作
- apache spark rdd方法作用是什么
- apache spark rdd分区
- apache spark rdd概述
- apache spark rdd容错
- apache spark rdd func方法作用是什么
- apache spark RDD特性
- apache spark精进rdd算子
- 大数据apache spark rdd
- apache spark rdd core
- apache spark rdd特点
- apache spark rdd关系
- apache spark初次学习rdd笔记
- apache spark rdd弹性
- apache spark rdd学习笔记
- apache spark rdd saveastextfile
- apache spark RDD依赖关系
- apache spark rdd属性
- apache spark rdd dataframe区别
- apache spark rdd scala
- apache spark rdd应用
- apache spark rdd依赖窄依赖
- apache spark rdd实操教程
- apache spark rdd分区优化
- apache spark RDD弹性分布式数据集
- apache spark rdd函数
- apache spark rdd动态
- apache spark rdd怎么做
- apache spark rdd概念学习算子
- apache spark rdd hdfs
- apache spark key rdd
- apache spark键值对pair rdd操作
- apache spark rdd collect作用是什么
- apache spark原理逻辑图rdd学习笔记
- apache spark读取rdd
apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作