Spark学习---day02、Spark核心编程(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(一)
前言 Spark计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是: RDD : 弹性分布式数据集 累加器:分布式共享只写变量 广播变量:分布式共享只读变量 接下...
[Spark精进]必须掌握的4个RDD算子之filter算子
返回第三章第四个filter:过滤 RDD在今天的最后,我们再来学习一下,与 map 一样常用的算子:filter。filter,顾名思义,这个算子的作用,是对 RDD 进行过滤。就像是 map 算子依赖其映射函数一样,filter 算子也需要借助一个判定函数 f,才能实现对 RDD 的过滤转换。所...

![[Spark精进]必须掌握的4个RDD算子之flatMap算子](https://ucc.alicdn.com/pic/developer-ecology/zpiaduicf3hfi_e3ad7bb61e7f433384eba5d01297be9e.png)
[Spark精进]必须掌握的4个RDD算子之flatMap算子
返回第二章第三个flatMap:从元素到集合、再从集合到元素flatMap 其实和 map 与 mapPartitions 算子类似,在功能上,与 map 和 mapPartitions 一样,flatMap 也是用来做数据映射的,在实现上,对于给定映射函数 f,flatMap(f) 以元素为粒度,...
![[Spark精进]必须掌握的4个RDD算子之mapPartitions算子](https://ucc.alicdn.com/pic/developer-ecology/zpiaduicf3hfi_6aa28486a4f647af98c0e6a99261bcab.png)
[Spark精进]必须掌握的4个RDD算子之mapPartitions算子
返回第一章第二个mapPartitions:以数据分区为粒度的数据转换按照介绍算子的惯例,我们还是先来说说 mapPartitions 的用法。mapPartitions,顾名思义,就是以数据分区为粒度,使用映射函数 f 对 RDD 进行数据转换。对于上述单词哈希值计数的例子,我们结合后面的代码,来...
[Spark精进]必须掌握的4个RDD算子之map算子
序章第一个map. 以元素为粒度的数据转换我们先来说说 map 算子的用法:给定映射函数 f,map(f) 以元素为粒度对 RDD 做数据转换。其中 f 可以是带有明确签名的带名函数,也可以是匿名函数,它的形参类型必须与 RDD 的元素类型保持一致,而输出类型则任由开发者自行决定。我们使用如下代码,...
Spark学习---2、SparkCore(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(二)
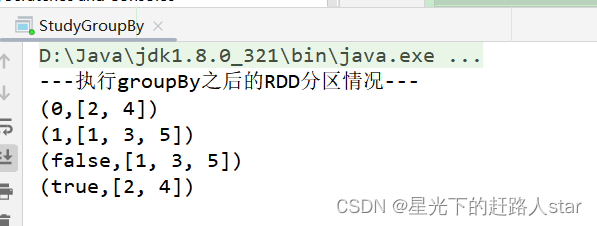
2.3.1.4 groupBy()分组1、用法:groupBy(f) ,以元素为粒度对每个元素执行函数f。2、函数f:(1)函数f为用户自定义实现内容,返回值任意(2) 函数返回值为算子groupBy返回值的key,元素为value。(3)算子groupBy...
Spark学习---2、SparkCore(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(一)
1、RDD概述1.1 什么是RDDRDD(Resilient Distributed Dataset)叫弹性分布式数据集,是Spark中对于分布式数据集的抽象。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。1.2 RDD五大特性1、一组分区,即是数据集的基本组成单...
Spark shuffle、RDD 算子【重要】
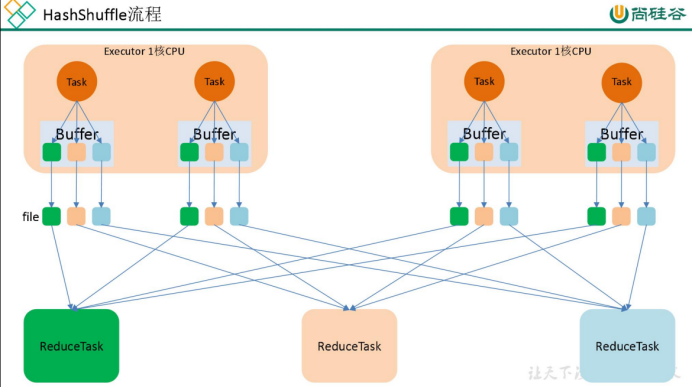
一、介绍一下 Spark shuffle:Spark shuffle 就是将分布在不同结点的数据按照一定的规则进行打乱重组。那么,说起 shuffle 就想到 MapReduce 中的 shuffle,MapReduce 中的 shuffle 是来连接 Map 和 Reduce 的桥梁,Map 的输...
[帮助文档] 如何在使用SparkShell和RDD(新)_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
本文为您介绍如何使用Spark Shell,以及RDD的基础操作。

Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(下)
3. 持久化持久化,也就是将 RDD 的数据缓存到内存中/磁盘中,以后无论对这个RDD做多少次计算,都是直接取这个RDD的持久化的数据,比如从内存中或者磁盘中,直接提取一份数据。可以使用 persist()函数来进行持久化,一般默认的存储空间是在内存中,如果内存不够就会写入磁盘中。persist 持...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache sparkrdd相关内容
- apache spark学习rdd依赖持久化
- apache spark rdd依赖
- apache spark RDD持久化
- apache spark编程rdd分区action
- apache spark学习RDD算子
- apache spark rdd分区规则
- apache spark rdd action
- apache spark学习rdd分区
- apache spark学习rdd
- apache spark rdd概述
- apache spark rdd分区
- apache spark rdd分区优化
- apache spark RDD操作
- apache spark精进rdd算子
- apache spark RDD编程
- 大数据apache spark rdd
- apache spark rdd dataframe区别
- apache spark rdd属性
- apache spark rdd学习笔记
- apache spark原理逻辑图rdd学习笔记
- apache spark初次学习rdd笔记
- apache spark rdd学习
- apache spark rdd hdfs
- apache spark rdd特点
- apache spark rdd动态
- apache spark rdd函数
- apache spark rdd方法
- apache spark rdd应用
- apache spark rdd实操教程
- apache spark rdd容错
- apache spark rdd作用是什么
- apache spark rdd方法作用是什么
- apache spark rdd func方法作用是什么
- apache spark rdd saveastextfile
- apache spark rdd collect作用是什么
- apache spark rdd关系
- apache spark rdd弹性
- apache spark rdd怎么做
- apache spark RDD特性
- apache spark RDD依赖关系
- apache spark rdd依赖窄依赖
- apache spark RDD弹性分布式数据集
- apache spark读取rdd
- apache spark rdd scala
- apache spark rdd core
- apache spark key rdd
- apache spark rdd概念学习
- apache spark rdd概念学习算子
apache spark更多rdd相关
apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作