讲解机器学习中的 K-均值聚类算法及其优缺点。
K-均值聚类算法是一种无监督学习算法,常用于对数据进行聚类分析。其主要步骤如下: 首先随机选择K个中心点(质心)作为初始聚类中心。 对于每一个样本,计算其与每一个中心点的距离,将其归到距离最近的中心点所在的聚类。 对于每一个聚类,重新计算其中所有样本的中心点位置。 重复以上步骤,直到聚类中心不再改变...
讲解机器学习中的 K-均值聚类算法及其优缺点。
K-均值聚类的步骤如下:随机选择 K 个点作为初始化质心。分别计算每个样本与所有质心之间的距离,将每个样本分配到与其距离最近的质心所在的簇中。更新质心,即将每个簇的质心移动到该簇中所有样本的平均位置。重复步骤 2 和 3,直到质心不发生变化或达到最大迭代次数。K-均值聚类算法的优点包括:简单而直观:...

机器学习中的 K-均值聚类算法及其优缺点
K-均值聚类算法是一种无监督学习算法,用于将数据分成K个不同的类别。该算法将每个数据点都视为一个向量,并通过计算各数据点之间的距离来确定它们所属的类别。具体地说,该算法的流程如下:选择K个随机的点作为初始聚类中心;对每个数据点,计算其与K个聚类中心之间的距离,并将其分配到距离最近的聚类中心所代表的类...
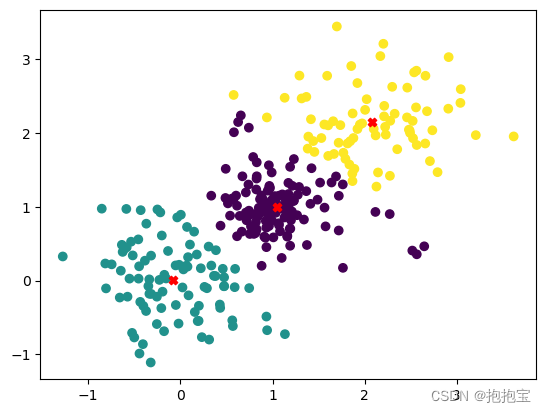
金融机器学习方法:K-均值算法
1.算法介绍K均值聚类算法是机器学习和数据分析中常用的无监督学习方法之一,主要用于数据的分类。它的目标是将数据划分为几个独特的、互不重叠的子集或“集群”,以使得同一集群内的数据点彼此相似,而不同集群的数据点则尽可能不同。2.算法原理选择K个初始质心,这些质心可以是随机选取的数据点或其他方法得到的。根...
[帮助文档] 机器学习线性支持向量机算法组件的配置及示例_人工智能平台 PAI(PAI)
支持向量机SVM(Support Vector Machine)是基于统计学习理论的一种机器学习方法,通过寻求结构风险最小化,提高学习机泛化能力,从而实现经验风险和置信范围最小化。本文介绍线性支持向量机算法组件的配置方法及使用示例。
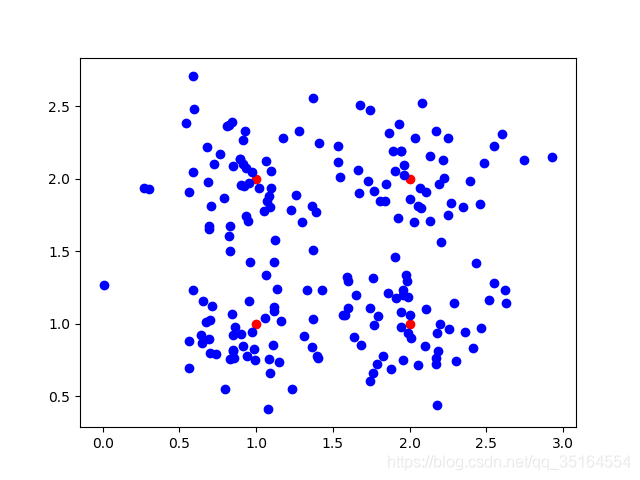
瞎聊机器学习——K-均值聚类(K-means)算法
本文中我们将会聊到一种常用的无监督学习算法——K-means。1、K-means算法的原理K-means算法是一种迭代型的聚类算法,在算法中我们首先要随机确定K个初始点作为质心,然后去计算其他样本距离每一个质心的距离,将该样本归类为距离最近的一个质心所属类别中(一个簇中)。举个例子来表述一下:如图所...
机器学习的K均值聚类算法使用的过程是什么呢?
机器学习的K均值聚类算法使用的过程是什么呢?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。










算法机器学习相关内容
- 机器学习算法
- 机器学习算法评价
- 机器学习树算法
- 机器学习决策算法
- 机器学习决策树算法
- 机器学习数据处理算法
- 构建机器学习算法
- 机器学习包裹特征选择算法
- 机器学习特征选择算法
- 机器学习算法推荐系统
- 机器学习算法xgboost
- 机器学习算法xgboost模型
- 机器学习算法模型
- 机器学习算法特征
- 机器学习深度学习算法
- 机器学习算法分类
- 机器学习算法随机森林
- 机器学习算法树
- 机器学习算法决策树
- 机器学习算法决策
- 机器学习算法示例
- 机器学习alink算法
- 机器学习算法方法
- 机器学习算法实践
- 机器学习算法文本分类
- 机器学习聚类算法
- 机器学习均值聚类算法
- 机器学习pai开源算法
- 机器学习集成学习算法
- 机器学习pai alink算法
- 机器学习算法评估
- 机器学习pai算法
- 机器学习easyrec算法
- 机器学习简介hello world算法knn
- 机器学习算法knn
- 机器学习算法实战
- 机器学习聚类算法源码
- 机器学习k-means算法实战源码
- 机器学习算法数据集
- 机器学习算法概率模型
- 机器学习kmeans聚类算法案例
- 机器学习kmeans聚类算法
- 机器学习朴素贝叶斯算法
- 机器学习算法指标
- 机器学习算法案例分析
- 机器学习xgboost算法
- 机器学习svm算法
- 机器学习决策算法分类
算法更多机器学习相关
- 机器学习近邻算法
- 机器学习算法svm
- 机器学习实战算法
- 阿旭机器学习算法
- 机器学习算法data
- ml回归预测机器学习算法参数data
- 机器学习算法集成
- 机器学习算法近邻
- 机器学习算法数据集分类
- 机器学习sklearn算法
- 机器学习算法鸢尾花
- 机器学习算法贝叶斯
- 机器学习算法支持向量机
- 机器学习算法公式推导
- 机器学习模型算法
- 机器学习算法均值聚类
- 机器学习分类算法集成学习算法
- 机器学习算法流程
- 机器学习算法深度学习
- 机器学习算法neighbors
- 机器学习集成学习boosting算法公式推导
- 回归预测机器学习算法系统data
- 机器学习随机森林算法
- 机器学习算法主成分
- 回归预测机器学习算法模型
- 机器学习概念算法
- 阿旭机器学习knn算法
- 入门机器学习算法
- 机器学习算法k近邻
- 机器学习近邻算法鸢尾花
- interview算法面试机器学习考点
- 机器学习apriori算法
- 阿旭机器学习实战knn算法
- 机器学习算法梯度下降
- 机器学习入门算法
- 算法岗位机器学习技术
- 机器学习测试笔记算法
- 机器学习算法naivebayes
- 机器学习算法pca分析
- 机器学习算法决策树随机森林实践
- 机器学习算法boston数据集
- 机器学习scikit-learn算法
- 机器学习集成算法
- 机器学习算法lightgbm
- 机器学习分类算法集成算法
- 机器学习原理算法
- ml回归预测机器学习算法
- 机器学习降维算法
- 机器学习pai实践算法
- 机器学习算法步骤