[帮助文档] 机器学习线性支持向量机算法组件的配置及示例
支持向量机SVM(Support Vector Machine)是基于统计学习理论的一种机器学习方法,通过寻求结构风险最小化,提高学习机泛化能力,从而实现经验风险和置信范围最小化。本文介绍线性支持向量机算法组件的配置方法及使用示例。
机器学习测试笔记(21)——朴素贝叶斯算法
1.朴素贝叶斯概率统计概念1.1数学公式 P(B|A)· P(A) P(A|B) = —————————— ...

机器学习测试笔记(10)——K邻近算法(下)
案例1:红酒分类上面我们采用make_blobs模拟数据来介绍K邻近算法,下面我们通过sklearn数据集来看一下K邻近算法的表现。 # 红酒案例 # 导入sklearn数据集 from sklearn import datasets def Sklean_wine(): #导入红酒数据集 wine...
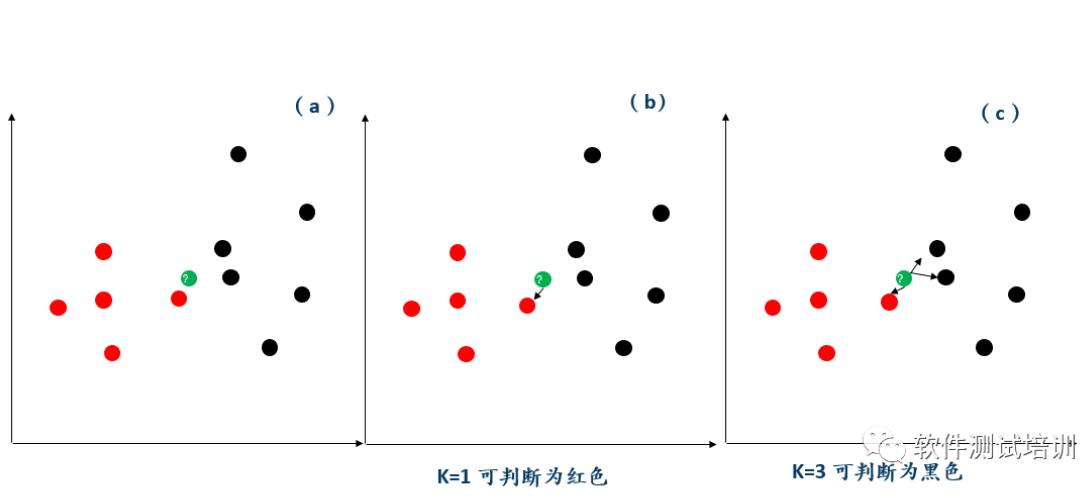
机器学习测试笔记(10)——K邻近算法(上)
监督学习和非监督学习我们谈起机器学习经常会听到监督学习和非监督学习,它们的区别在哪里呢?监督学习是有标签的,而非监督学习是没有标签的。比如有一批酒,我们知道里面包括红酒和白酒,算法f可以用于鉴别某一个酒是否为红酒和白酒,这时候算法f就称作为监督学习,红酒、白酒即为标签。如果现在另有一批酒...
数学建模国赛:python机器学习基础之训练集和测试集拆分、算法精确率评估
在实际训练中,经常会把训练数据进一步拆分成训练集和测试集这样有助于模型选取。想要数据集或者有不明白的请点赞关注后私信博主Sklearn中的train_test_spilt函数是交叉验证常用的函数,功能是从样本中随机地按比例选取训练集和测试集原数据如下:拆分后效果如下 ton代码如下from sk...
机器学习中的测试算法是什么呢?
机器学习中的测试算法是什么呢?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐

社区圈子




最佳实践





算法机器学习相关内容
- 机器学习算法
- 机器学习树算法
- 机器学习算法pca
- 机器学习聚类k-means算法
- 机器学习算法区别
- 机器学习算法度量
- 机器学习算法pagerank
- 机器学习规则apriori算法
- 机器学习k-means聚类算法
- 机器学习算法调优
- 机器学习算法性能
- 机器学习算法简介
- 树算法机器学习
- 机器学习支持向量机svm算法
- 机器学习算法线性回归决策树
- ai人工智能机器学习算法
- 机器学习算法神经网络
- 机器学习算法逻辑回归决策树随机森林
- 机器学习算法概念
- 机器学习算法评价
- 机器学习算法k-nearest knn
- 机器学习算法k-nearest neighbors
- learning机器学习算法
- 机器学习决策算法
- 机器学习决策树算法
- 开发机器学习算法
- 机器学习数据处理算法
- 构建机器学习算法
- 机器学习包裹特征选择算法
- 机器学习特征选择算法
- 机器学习算法推荐系统
- 机器学习算法xgboost
- 机器学习算法xgboost模型
- 机器学习算法模型
- 机器学习算法特征
- 机器学习深度学习算法
- 机器学习算法分类
- 机器学习算法随机森林
- 机器学习算法树
- 机器学习算法决策树
- 机器学习算法决策
- 机器学习算法示例
- 机器学习alink算法
- 机器学习算法方法
- 机器学习算法实践
- 机器学习算法文本分类
- 机器学习聚类算法
- 机器学习均值算法
- 机器学习均值聚类算法
算法更多机器学习相关
- 机器学习集成学习算法
- 机器学习近邻算法
- 机器学习算法实战
- 机器学习算法svm
- 机器学习算法聚类
- 机器学习实战算法
- 阿旭机器学习算法
- 机器学习算法源码
- 机器学习算法data
- ml回归预测机器学习算法参数data
- 机器学习朴素贝叶斯算法
- 机器学习算法knn
- 机器学习算法数据集
- 机器学习算法集成
- 机器学习算法近邻
- 机器学习算法数据集分类
- 机器学习sklearn算法
- 机器学习算法鸢尾花
- 机器学习算法贝叶斯
- 机器学习算法支持向量机
- 机器学习算法公式推导
- 机器学习模型算法
- 机器学习算法均值聚类
- 机器学习算法lda
- 机器学习分类算法集成学习算法
- 机器学习算法组件
- 类机器学习算法
- 机器学习算法指标
- 机器学习xgboost算法
- 机器学习算法流程
- 机器学习算法深度学习
- 机器学习算法neighbors
- 机器学习集成学习boosting算法公式推导
- 回归预测机器学习算法系统data
- 机器学习随机森林算法
- 机器学习算法主成分
- 回归预测机器学习算法模型
- 机器学习概念算法
- 阿旭机器学习knn算法
- 机器学习pai算法
- 入门机器学习算法
- 机器学习算法k近邻
- 机器学习算法自定义
- 机器学习近邻算法鸢尾花
- interview算法面试机器学习考点
- 机器学习apriori算法
- 阿旭机器学习实战knn算法
- 机器学习算法梯度下降
- 机器学习入门算法
- 算法岗位机器学习技术