
【视频】R语言LDA线性判别、QDA二次判别分析分类葡萄酒品质数据|数据分享(下)
【视频】R语言LDA线性判别、QDA二次判别分析分类葡萄酒品质数据|数据分享(上):https://developer.aliyun.com/article/1497224 非线性模型 在 GAM 模型中,只有挥发性酸度的自由度等于 1,表明线性关联,而对所有其他 10 个变量应用平滑样条。 结果表...
【视频】R语言LDA线性判别、QDA二次判别分析分类葡萄酒品质数据|数据分享(上)
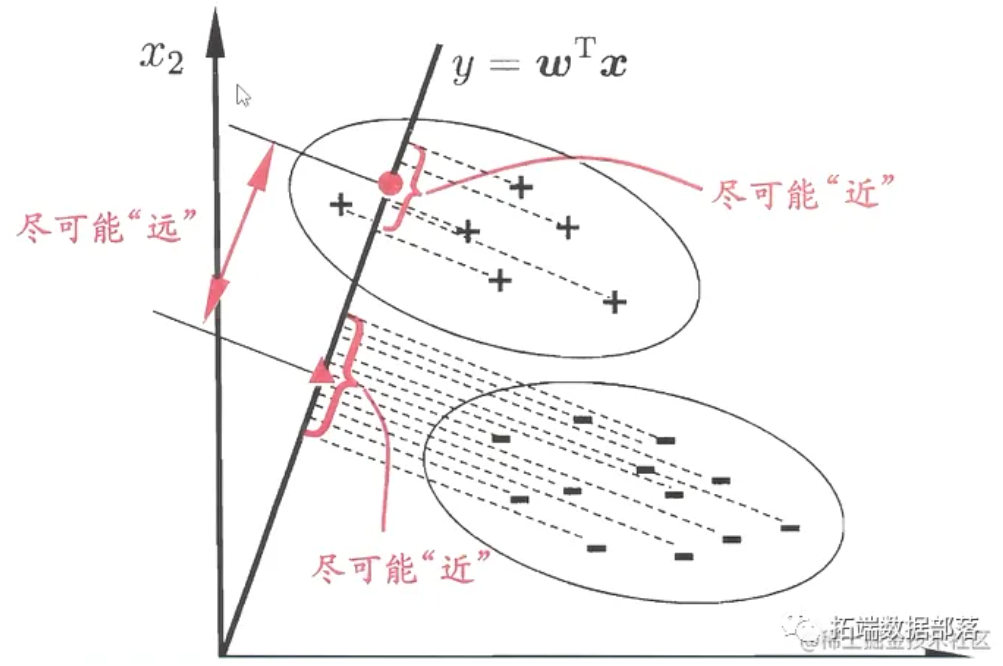
全文链接:https://tecdat.cn/?p=33031 分析师:Donglei Niu 判别分析(Discriminant analysis)是一种统计分析方法,旨在通过将一组对象(例如观察数据)分类到已知类别的组中,来发现不同组之间的差异(点击文末“阅读原文”获取完整代码数据)。 什么是判...

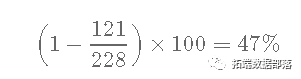
【视频】R语言生存分析原理与晚期肺癌患者分析案例|数据分享(下)
【视频】R语言生存分析原理与晚期肺癌患者分析案例|数据分享(上):https://developer.aliyun.com/article/1495622 Xx年生存率常常被错误估计 如果 使用“天真”的估计会怎样? 228名患者中的121名到1年时死亡,因此: ...

【视频】R语言生存分析原理与晚期肺癌患者分析案例|数据分享(上)
生存分析的名称源于临床研究,其中预测死亡时间,即生存,通常是主要目标。 生存分析是一种回归问题(人们想要预测一个连续值),但有一个转折点。它与传统回归的不同之处在于,在生存分析中,结果变量既有一个事件,也有一个与之相关的时间值,部分训练数据只能被部分观察——它们是被删失的。本文用R语言生存分析晚期肺...

【视频】什么是非线性模型与R语言多项式回归、局部平滑样条、 广义相加GAM分析工资数据|数据分享(下)
【视频】什么是非线性模型与R语言多项式回归、局部平滑样条、 广义相加GAM分析工资数据|数据分享(上):https://developer.aliyun.com/article/1492364 广义加性模型 GAM模型提供了一个通用框架,可通过允许每个变量的非线性函数扩展线性模型,同时保持可加性。 ...
【视频】什么是非线性模型与R语言多项式回归、局部平滑样条、 广义相加GAM分析工资数据|数据分享(上)
全文链接:http://tecdat.cn/?p=9706 在这文中,我将介绍非线性回归的基础知识。非线性回归是一种对因变量和一组自变量之间的非线性关系进行建模的方法。最后我们用R语言非线性模型预测个人工资数据(查看文末了解数据获取方式)是否每年收入超过25万。 这些数据点对应于一段时间内的中国国内...

【视频】R语言极值理论EVT:基于GPD模型的火灾损失分布分析|数据分享(下)
【视频】R语言极值理论EVT:基于GPD模型的火灾损失分布分析|数据分享(上):https://developer.aliyun.com/article/1492333 四、摩天大楼 另一个有趣的应用是对摩天大楼的数据建模并检查其高度和楼层数的限制。全球摩天大楼的数据来自高层建筑和城市人居委员会 (...
【视频】R语言极值理论EVT:基于GPD模型的火灾损失分布分析|数据分享(上)
全文链接:http://tecdat.cn/?p=21425 “In cauda venenum”是您在极值理论一书中看到的第一句话:Laurens de Haan 和 Anna Ferreira 的介绍,这是关于您在应用 EVT 时将要处理的数据的性质的非常富有表现力的句子,极端数据通常具有更重要...
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福指数可视化|数据分享(下)
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福指数可视化|数据分享(上):https://developer.aliyun.com/article/1491650 欧氏距离 我们将使用欧几里得距离找到彼此最相似的国家,并将它们分组在一起。 ...

【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福指数可视化|数据分享(上)
原文链接:http://tecdat.cn/?p=24198 聚类是将总体或数据点划分为多个组的任务,以使同一组中的数据点与同一组中的其他数据点更相似,而与其他组中的数据点不相似。它基本上是基于它们之间的相似性和相异性的对象的集合。 在本项目中,我将使用世界幸福报告中的数据(查看文末了解数据获取方式...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
r语言分析相关内容
- r语言聚类分析可视化
- r语言实战分析
- r语言因子分析数据分析
- r语言聚类分析分析
- r语言分类分析
- r语言分析价值
- r语言分析数据可视化
- r语言pca主成分分析可视化
- r语言分析信用
- r语言分析数据实例
- r语言pca分析数据
- r语言分析数据可视化数据
- r语言分析实例
- r语言分析指标
- r语言pca分析可视化
- r语言主成分分析pca
- r语言神经网络分析
- r语言主成分分析数据
- r语言pca分析
- r语言pca主成分分析
- r语言分析可视化
- r语言聚类主成分分析
- r语言分析pca
- r语言分析可视化数据
- r语言指数分析可视化
- r语言股价分析
- r语言逻辑回归分析分类
- r语言逻辑回归分析分类数据
- r语言分析房价
- r语言lda分析
- r语言研究分析
- r语言模型分析可视化
- r语言变量分析
- r语言分析分类
- r语言garch分析
- r语言指数分析
- r语言模型分析
- r语言分析分类数据
- r语言knn分析
- r语言逻辑回归分析
- r语言lda分析数据
- r语言gam分析
- r语言检验分析
- r语言误差分析
- r语言主成分pca分析
- r语言模型研究分析
- r语言树分析数据
- r语言主成分pca树分析
- r语言决策树分析数据
r语言更多分析相关
- 数据r语言分析
- r语言分析序列
- r语言线性模型分析
- r语言序列分析
- r语言广义分析
- 视频r语言分析
- r语言贝叶斯分析
- r语言分析案例
- r语言广义线性模型分析
- r语言线性分析
- r语言var分析
- r语言模型分析序列
- r语言arima分析
- r语言效应分析
- r语言glm分析
- r语言线性回归分析
- r语言广义glm分析
- r语言分析指数
- r语言广义分析数据
- r语言分析股票
- r语言平滑分析
- r语言线性模型分析数据
- r语言广义模型分析
- r语言分析调查
- 数据r语言逻辑回归分析
- r语言广义逻辑回归分析
- r语言层次分析
- r语言判别分析
- r语言分析患者
- r语言贝叶斯模型分析
- r语言方差分析
- 分析r语言
- r语言树分析
- r语言泊松分析
- r语言股票分析
- r语言lasso分析
- r语言因子分析
- r语言逻辑回归logistic分析
- r语言线性分析数据
- r语言模型分析股票
- r语言模型分析指数
- r语言效应模型分析
- r语言分析投资
- r语言建模分析
- 数据r语言分析调查
- r语言分析葡萄酒
- r语言对数分析
- r语言分析数据集
- 数据r语言分析数据可视化
- r语言arima var分析